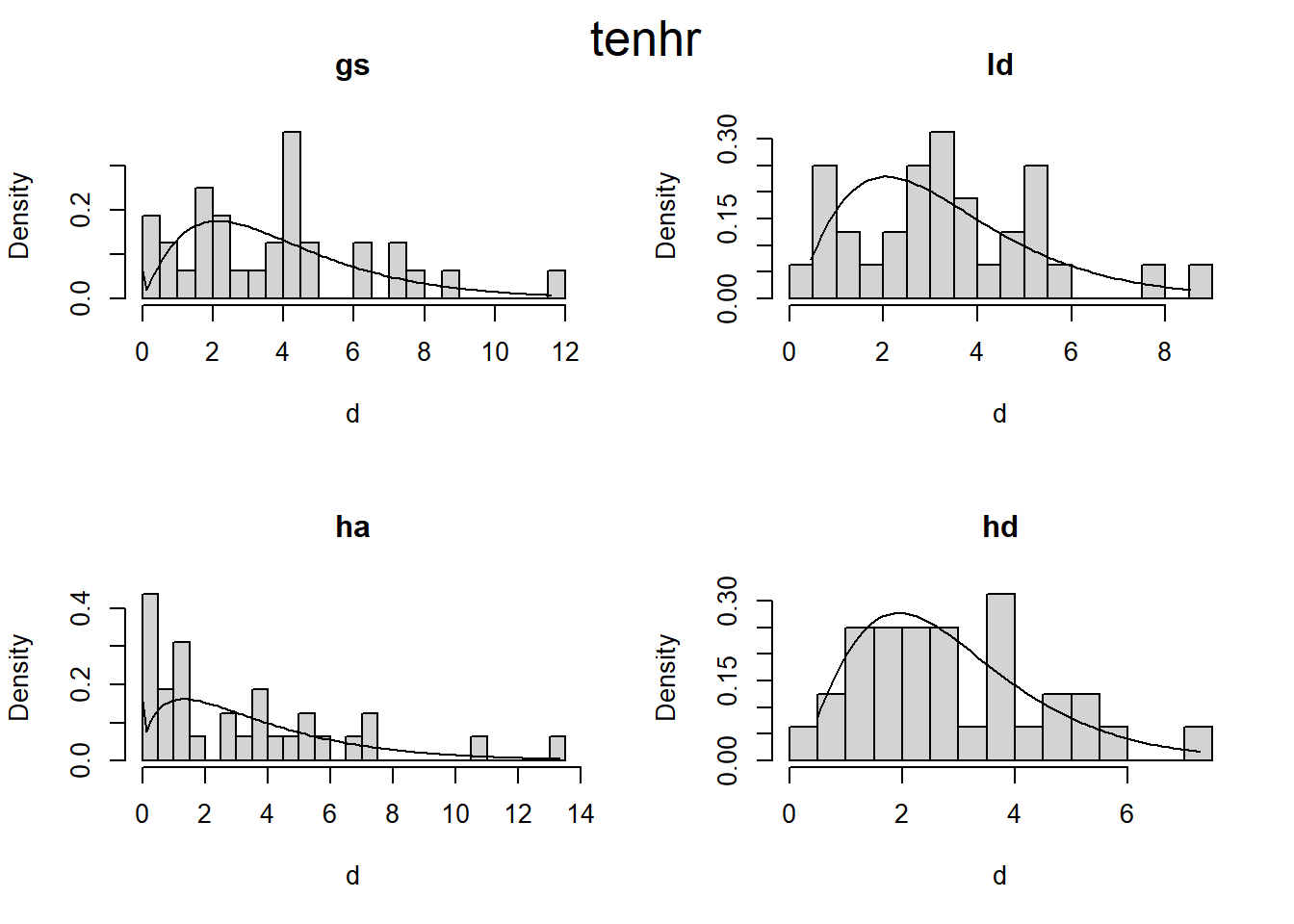
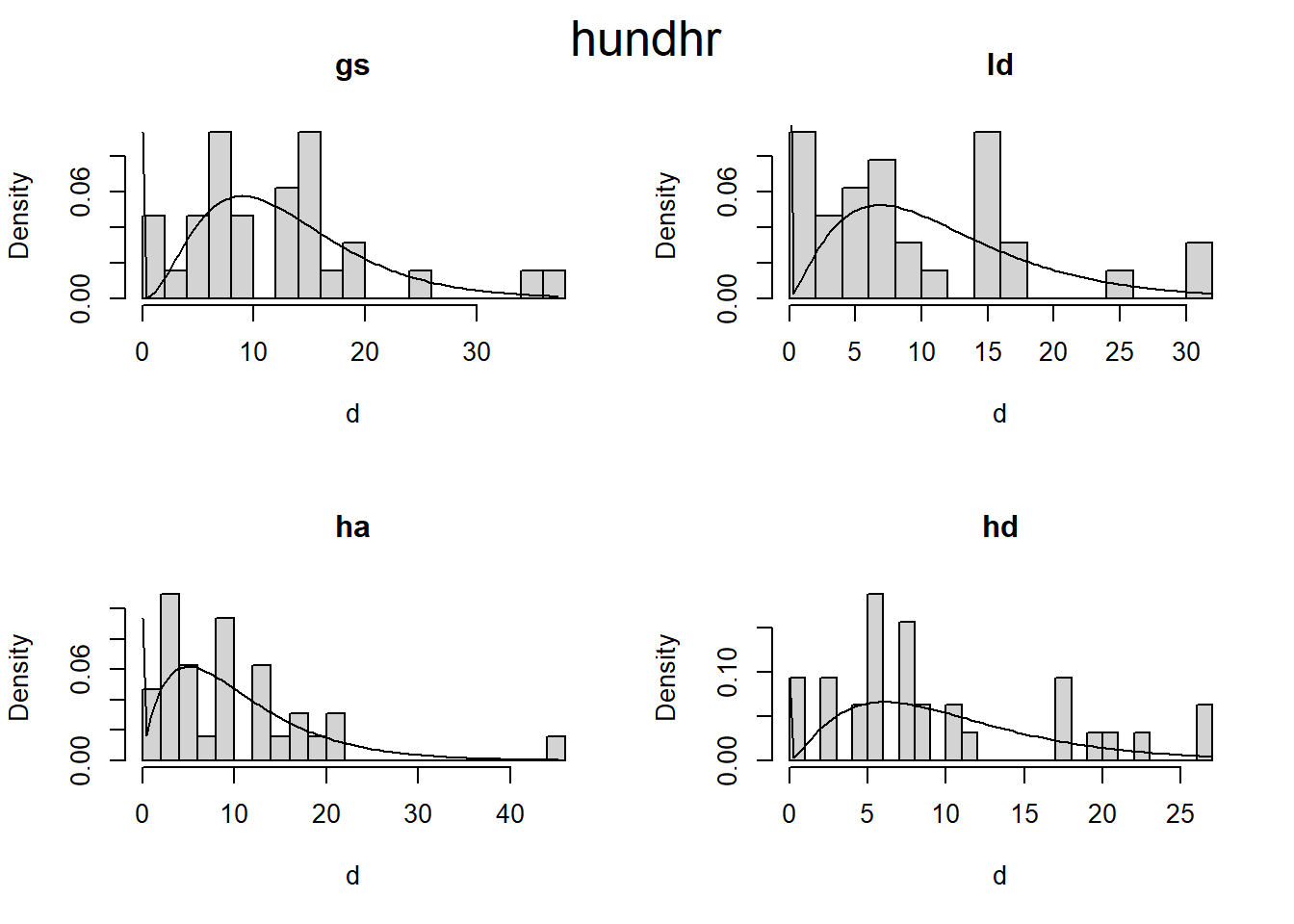
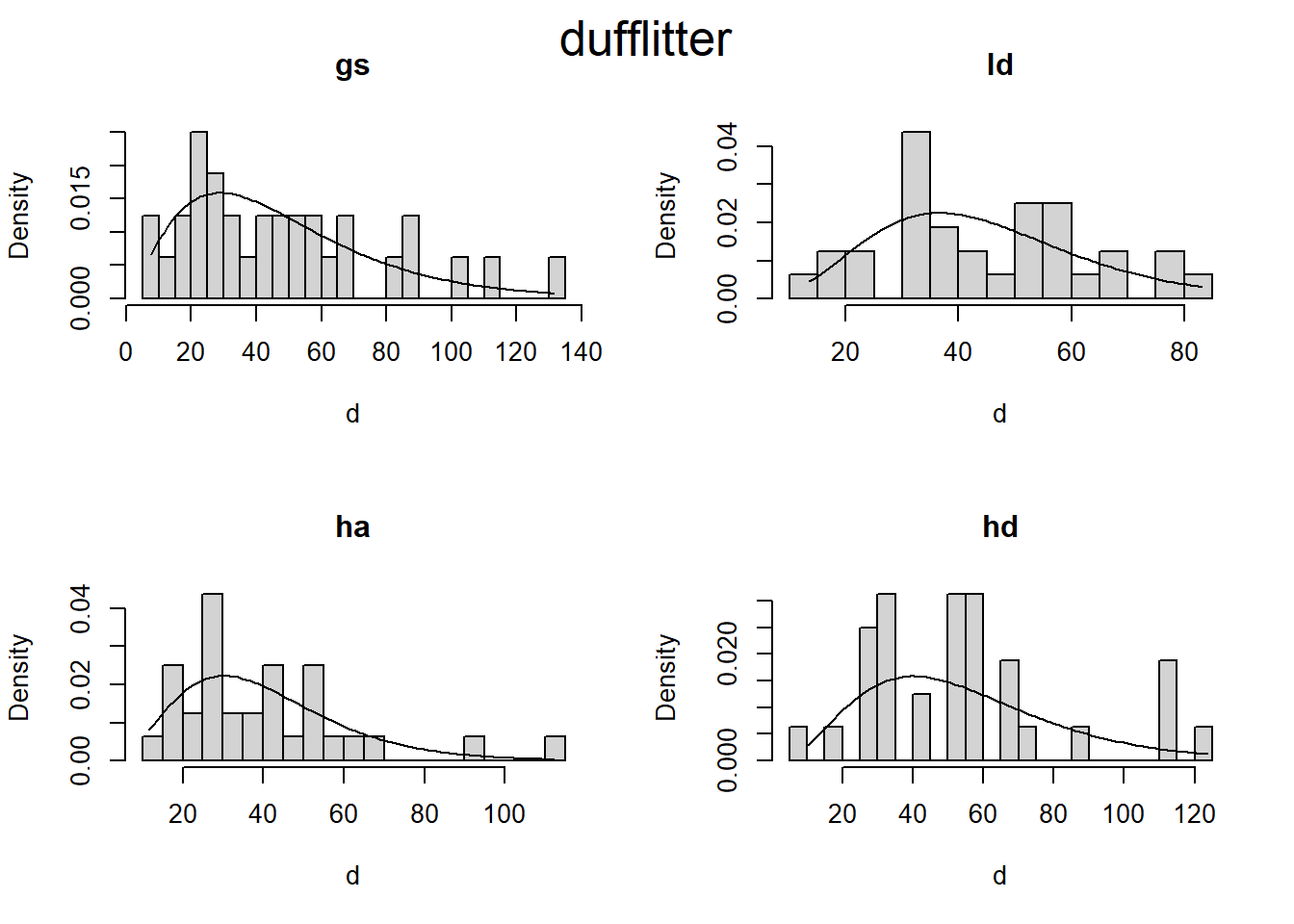
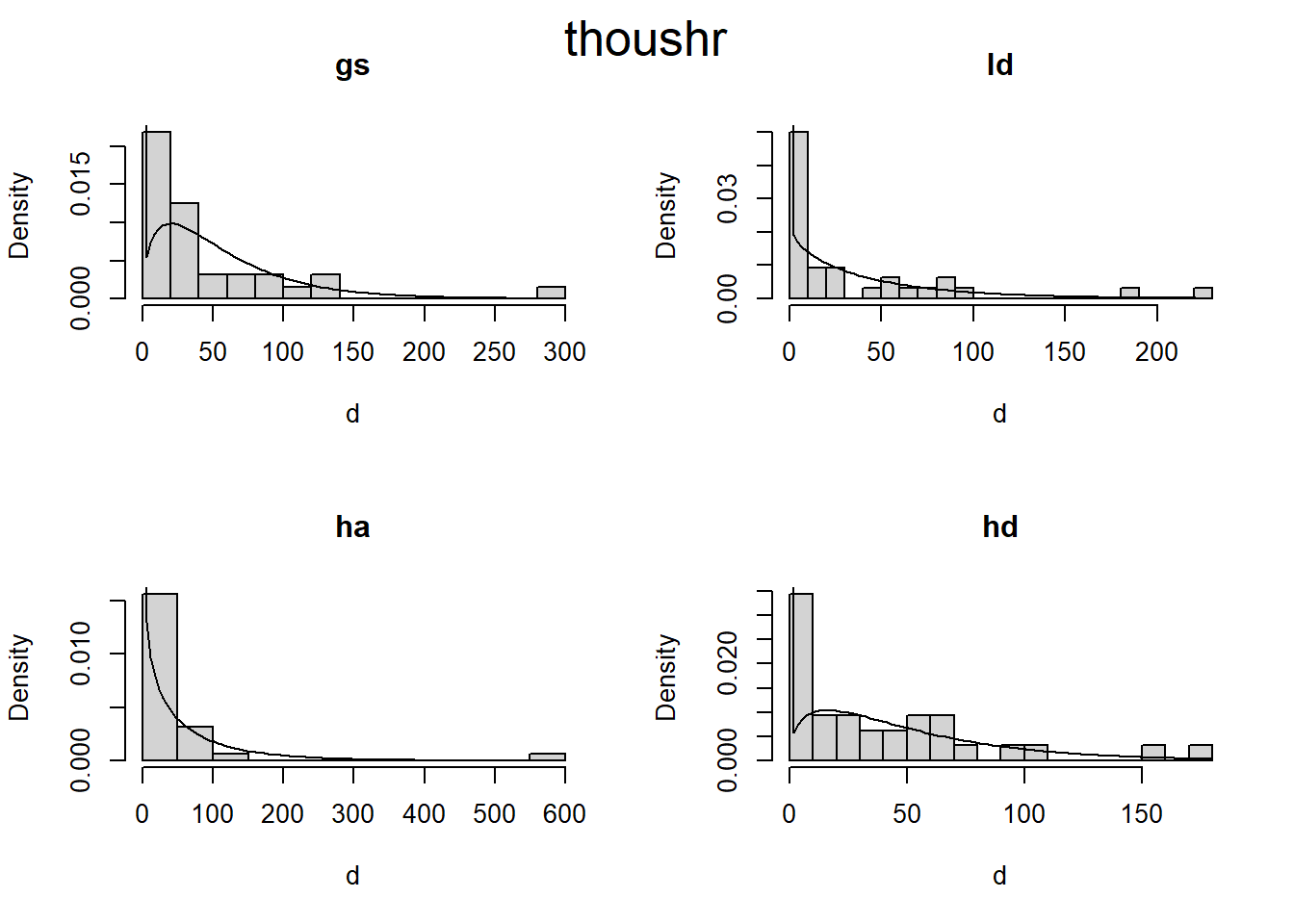
Are there differences in fuel loading between treatments before and after pct?
If so, what fuel loading components differ, and in which treatments before and after pct?
What is the magnitude of the difference (for each fuel class) by treatment before and after pct?
We have a range of response variables that include loading in several different classes of surface fuels. Some of these may be correlated with each other, which may have an effect on our interpretation of differences between treatments. For instance, if duff-litter load is negatively correlated with vegetation, even if we don’t see differences between treatment in either of these variables separately, it might be found that for any given level of vegetation loading, one treatment, or another may have consistently higher levels of duff-litter. I will be analyzing fuel loading categories independently. While not ideal, this simplifies the analysis.
In addition to correlation among classes, there may also be overlap. Primarily, this would be relevant to the 1-hr and duff/litter classes. We used a cutoff between redwoowd sprays that were counted as 1-hr fuels at about 2mm. These same 1-hr fuels were also included in the duff/litter depth because they were usually thouroughly mixed with the litter. For this reason, it is not possible to simply add these two classes.
Similarly, fuel beds after pct were covered with substantial slash, often precluding the ability to measure duff/litter. Furthermore, as a result of an oversight in the sampling protocol, leaves suspended in slash were not addressed, as they were neither captured as litter or 1-hr fuels. But these would be expected to contribute significantly to fire behavior after curing. It is also unclear how long long the slash leaves will remain suspended — we would expect this to vary by species — and their impact on fire behavior would be expected to change dramatically with their spatial arrangement (bulk density), with reduced behavior as they settle to the forest floor. For this reason, comparisons of duff/litter and 1-hr fuels before and after pct would be difficult to interpret.
Finallly, because herbaceous vegetation played a relatively minor role in our plots, it was lumped together with woody vegetation.
I opt to restrict quantitative comparisons to between treatments, before and after pct seperately.
In order to assess potential outliers, co-linearity, interactions, and other problems with statistical tests, we’ll first conduct some data exploration as outlined by Zuur et al. (2010).
For reference, here is a list of the fuel loading (response) variables of interest.
duff/litter load
woody vegetation
one hr fuels
ten hr fuels
hundred hr fuels
coarse woody debris
It’s important to note that variables 1 and 2 were measured twice per transect and the rest were measured once per transect. All analysese were conducted at the transect level–variables 1-3 were analyzed at their transect average (average of two observations per transect.) This was done to simplify the analysis.
4.1 Basic Summary
Code
# function to access mostly raw data, but with combined veg and thoushr fuels.# and select the output variables (`...`)load2 <-function(shape ="wide", pct =c("pre", "post", "both"), ...) { pct <- pct[1] pct_filter <-switch(pct,pre ="prepct", post ="postpct", both ="prepct|postpct" ) tl <-filter(total_load, phase == pct_filter) load_vars <-c("onehr", "tenhr", "hundhr", "dufflitter", "thoushr", "veg", "veg_diff")# TODO: if(pct == "post")if (!missing(...)) tl <-select(tl, ...)if (shape =="long") { tl <-pivot_longer(tl,-any_of(c("phase", "site", "treatment", "corner", "azi")),names_to ="class",values_to ="load" ) load_vars <- load_vars[load_vars %in% tl$class] tl <-mutate(tl, class =factor(class, levels = load_vars)) |>filter(!is.na(load)) } tl}
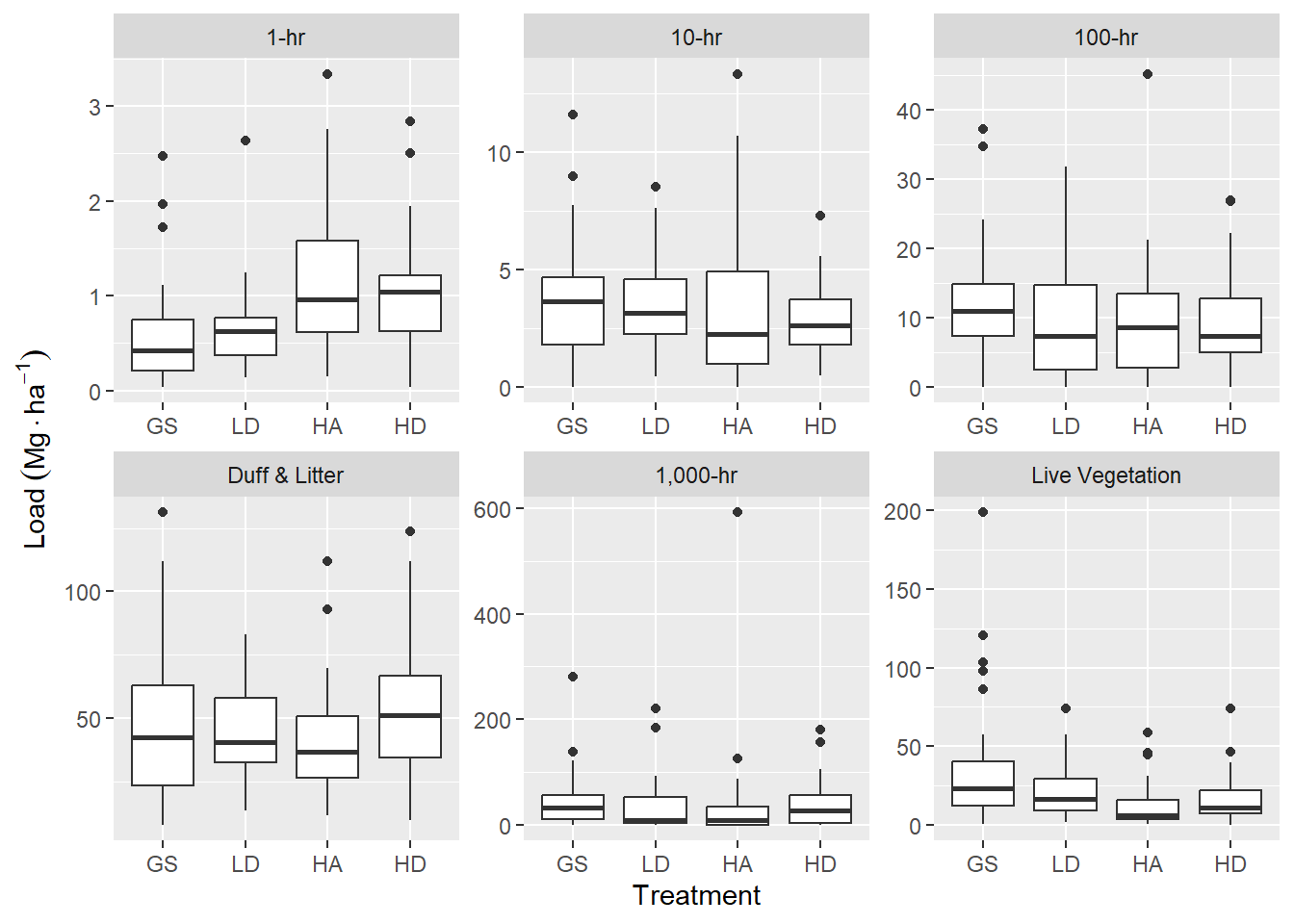
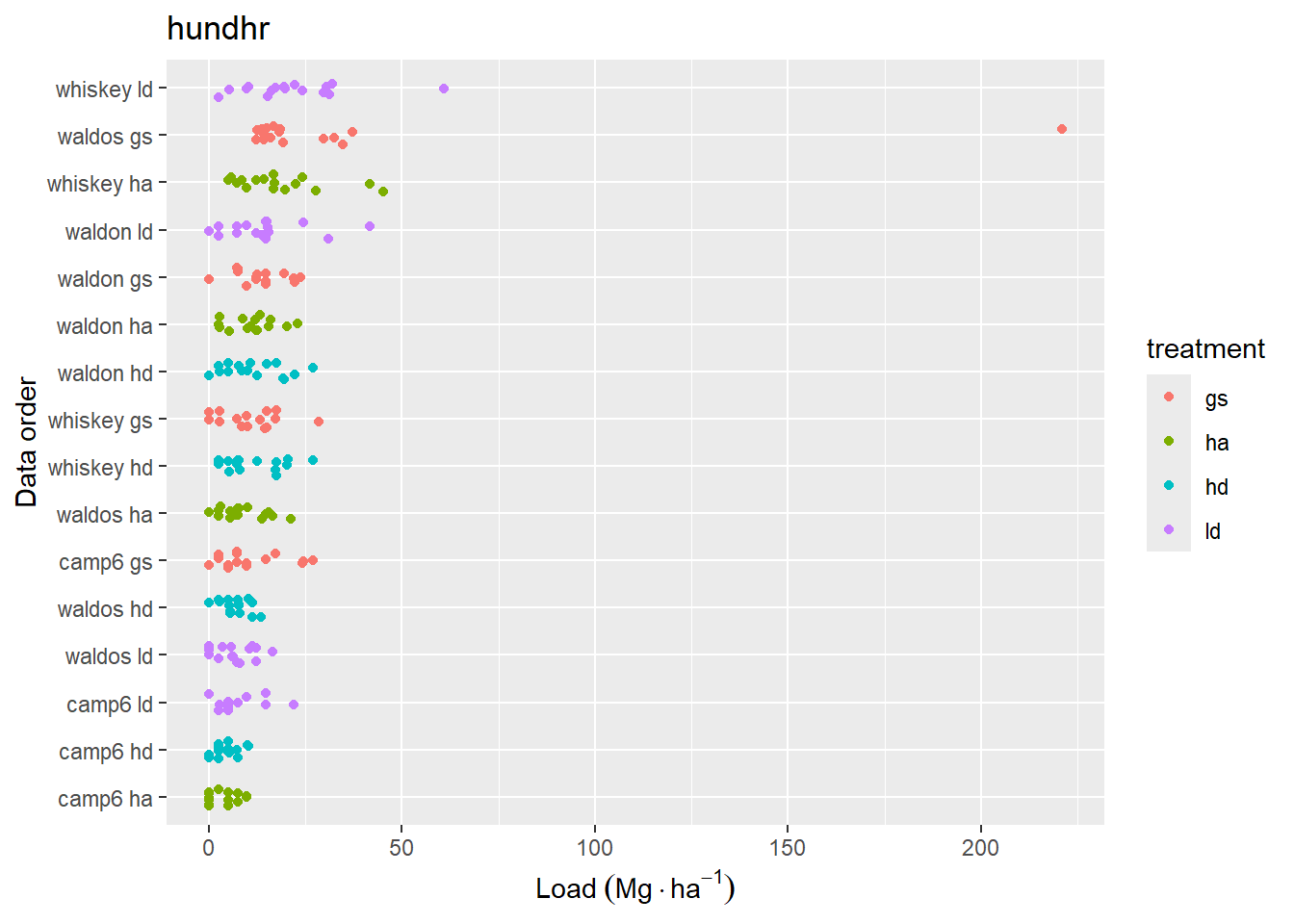
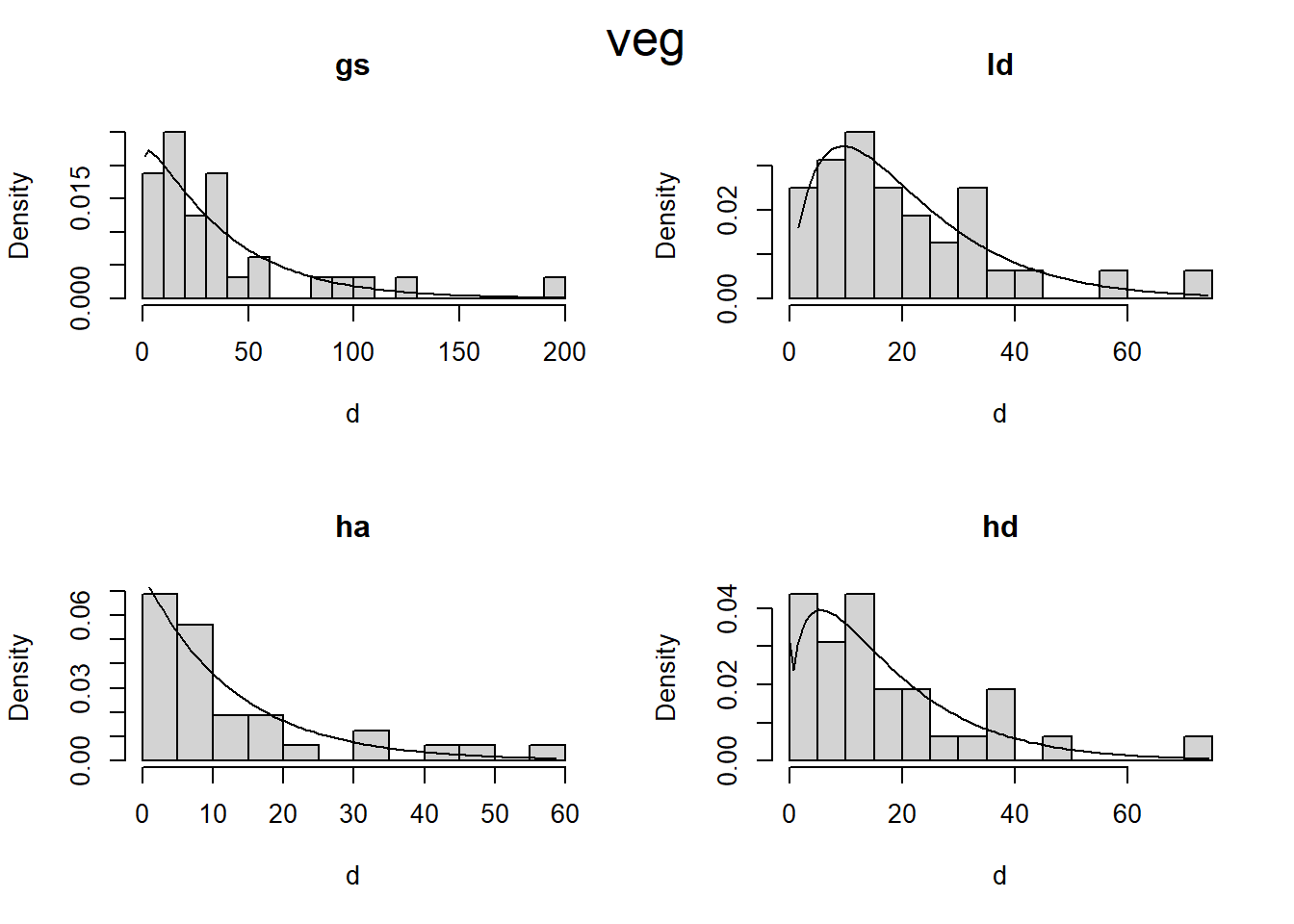
These plots seem to indicate that, pre-pct, there is slightly higher 1-hr fuel load for HA and HD, compared to GS and LD. Ten years after harvest, we would expect 1-hr fuels to be dominated by twigs and branches falling from live crowns and there is ostensibly a greater crown volume in the HA and HD treatments. Duff and litter may be slightly higher in the HD treatment, compared to the others. For live fuels, there appears to be a decreasing trend from GS > LD > HA & HD. Most of live fuel is due to regenerating sprouts. The difference in sprout growth in high vs. low light environments was readily apparent in the field.
Ten-hr and 100-hr, and 1000-hr fuels do not reveal an obvious trend. I’m not sure why this is at the moment.
Figure 4.1: Boxplots of fuels data summarized for six fuel classes across four overstory harvest treatments, prior to pre-commercial thinning, 10 years after harvest. Woody and herbaceous vegetation have been combined and sound and rotten, 1,000-hr fuels have been combined.
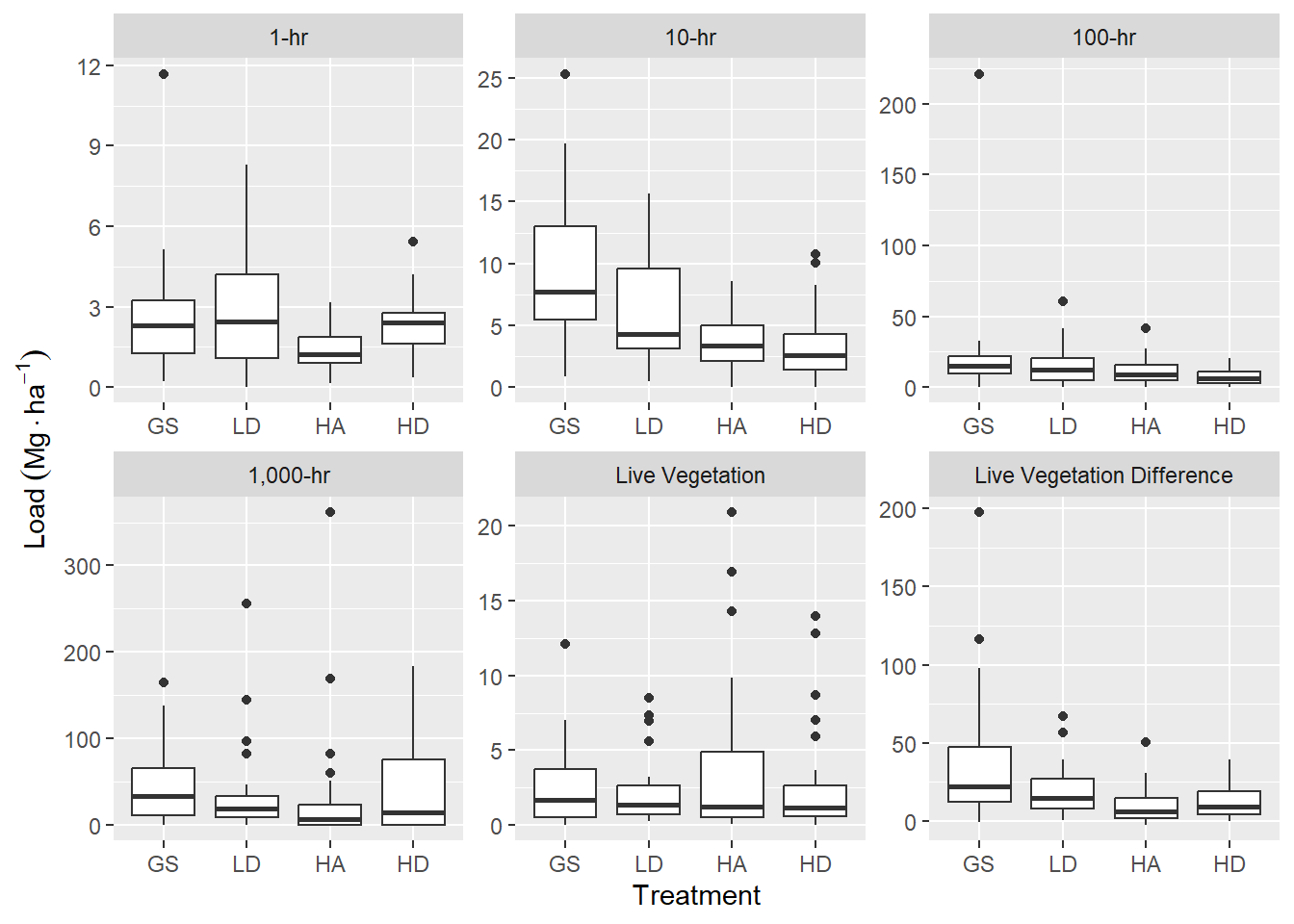
Figure 4.2: Boxplots of transect level fuels data summarized for six fuel classes across four overstory harvest treatments, following pre-commercial thinning, 10 years after harvest. Woody and herbaceous vegetation have been combined and sound and rotten, 1,000-hr fuels have been combined. Duff and litter data was not collected for this phase of the experiment. One-hour fuels do not included leaves suspended in the slash. Vegetation difference is the difference in pre- and post-pct vegetation fuels and represents vegetation slash recruited to the forest floor.
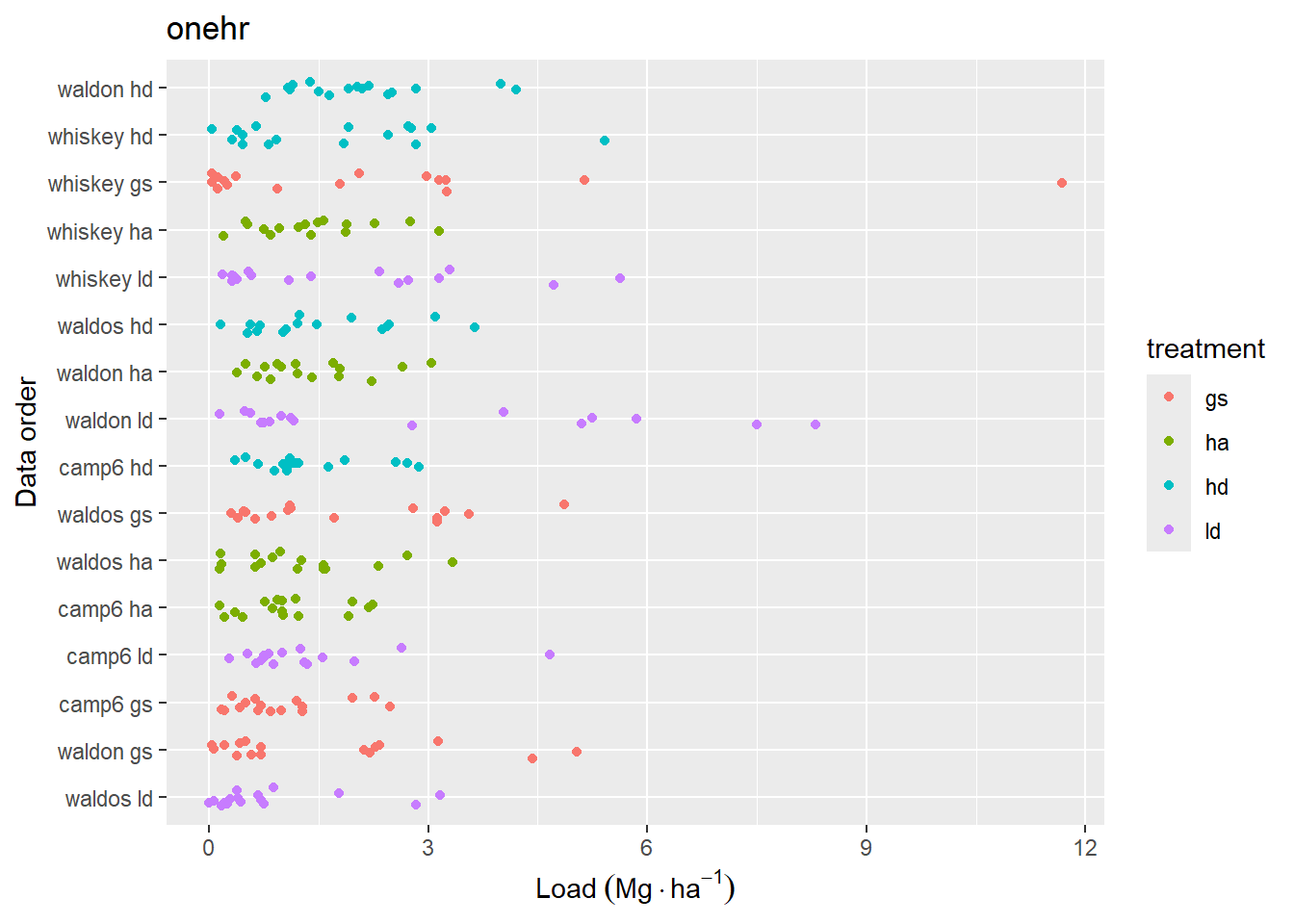
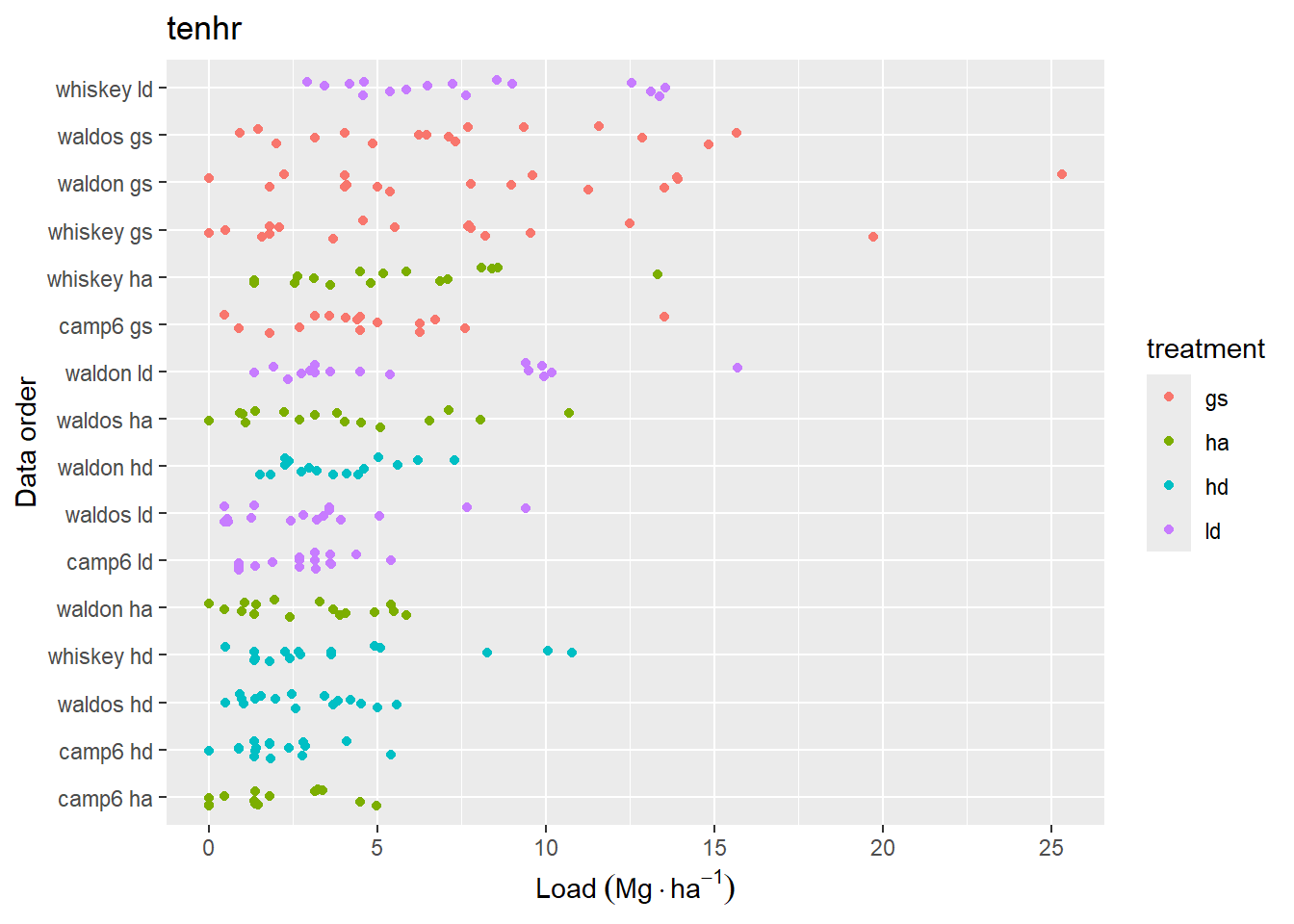
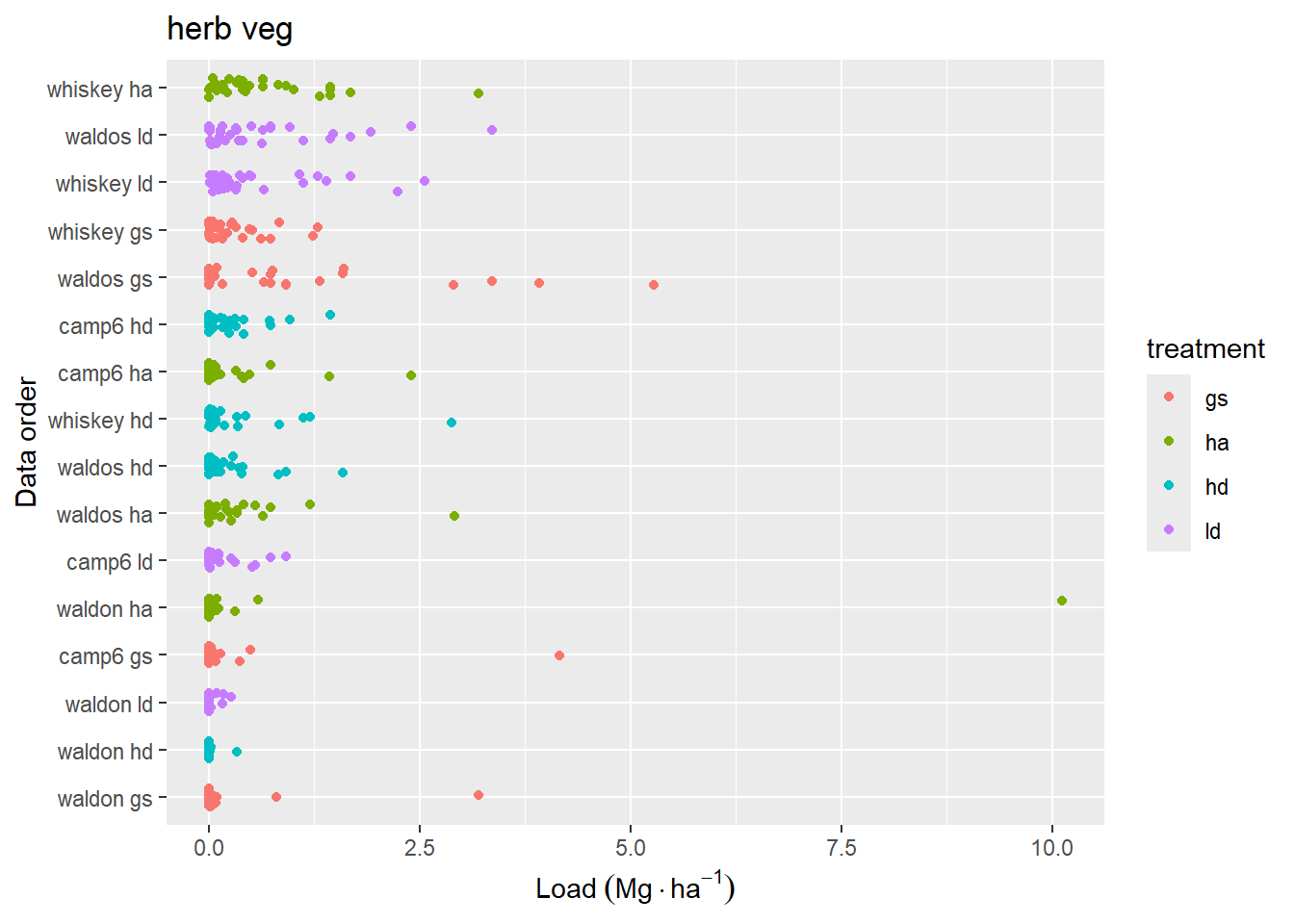
Figure 4.3: Data distribution of loading for fine woody debris classes. Data are sorted by mean loading within each replicate. Jitter has been added to aid in visual interpretation.
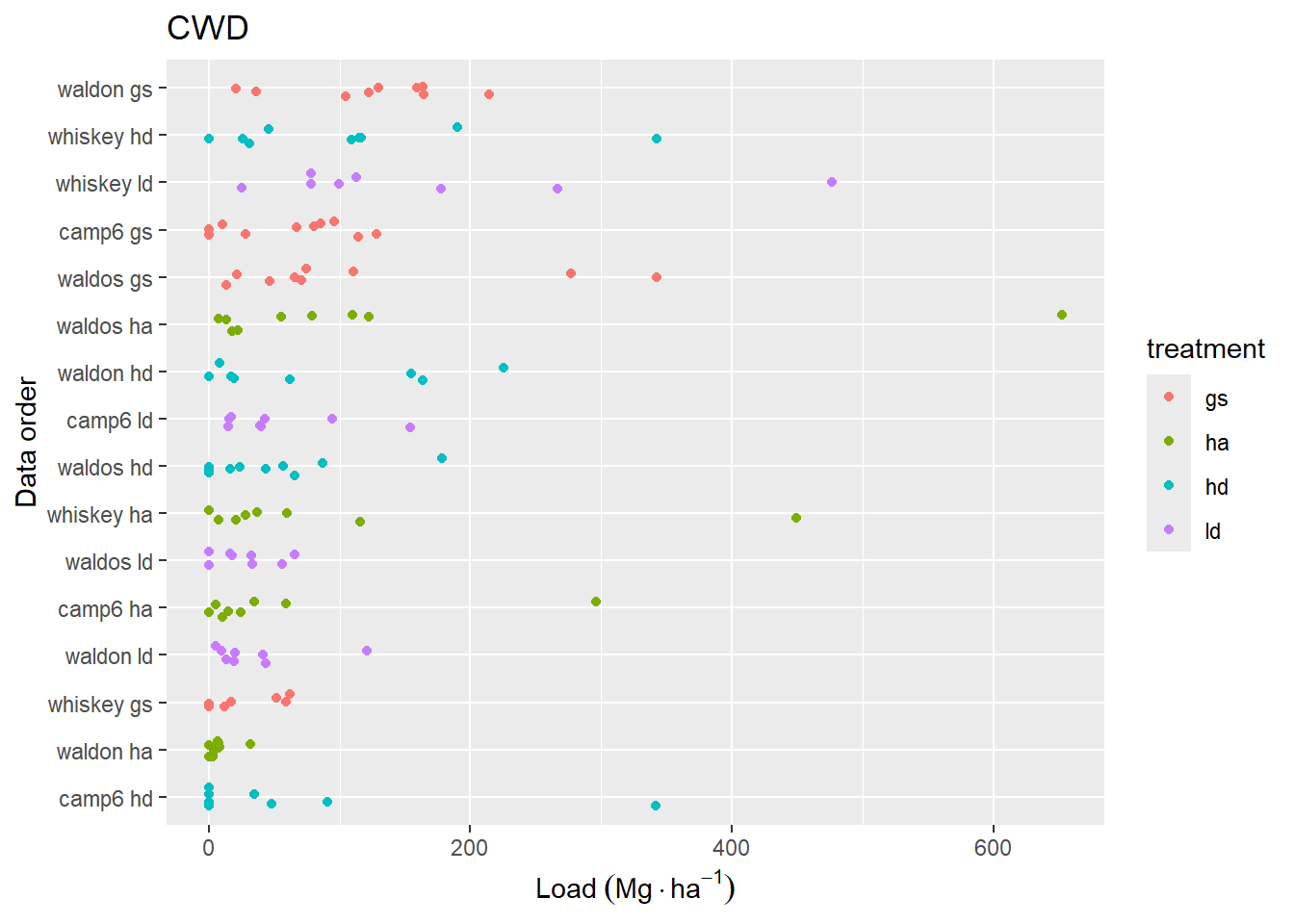
Figure 4.4: Sum of coarse woody (>7.64 cm, sound and rotten wood combined) fuel loading for transects. The y-axis is sorted by mean CWD loading for each replicate.
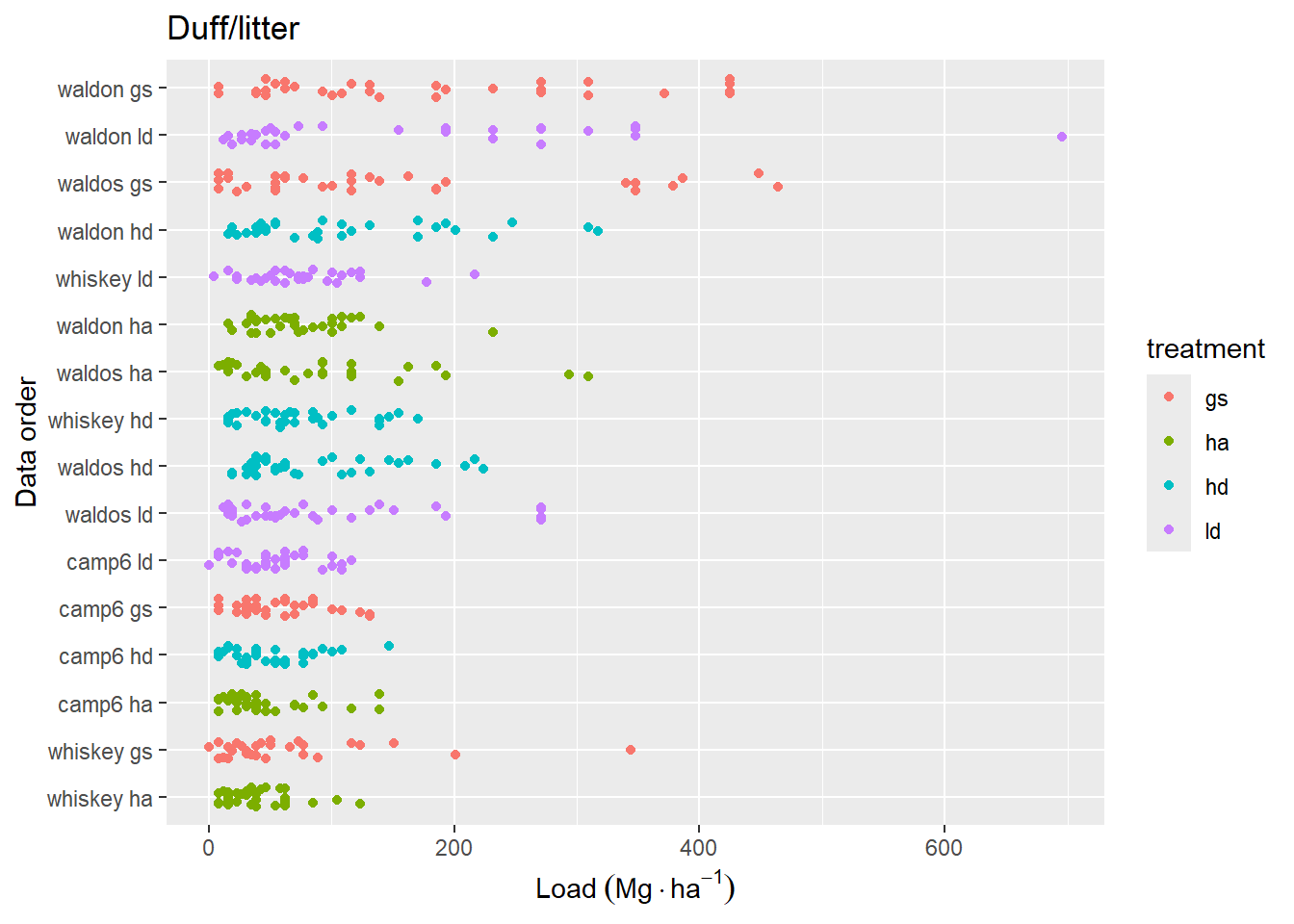
Figure 4.5: Combined duff and litter loading at each station along trancects. Y-axis is sorted as in Figure 4.4.
Warning: Removed 1 row containing missing values or values outside the scale range
(`geom_point()`).
Removed 1 row containing missing values or values outside the scale range
(`geom_point()`).
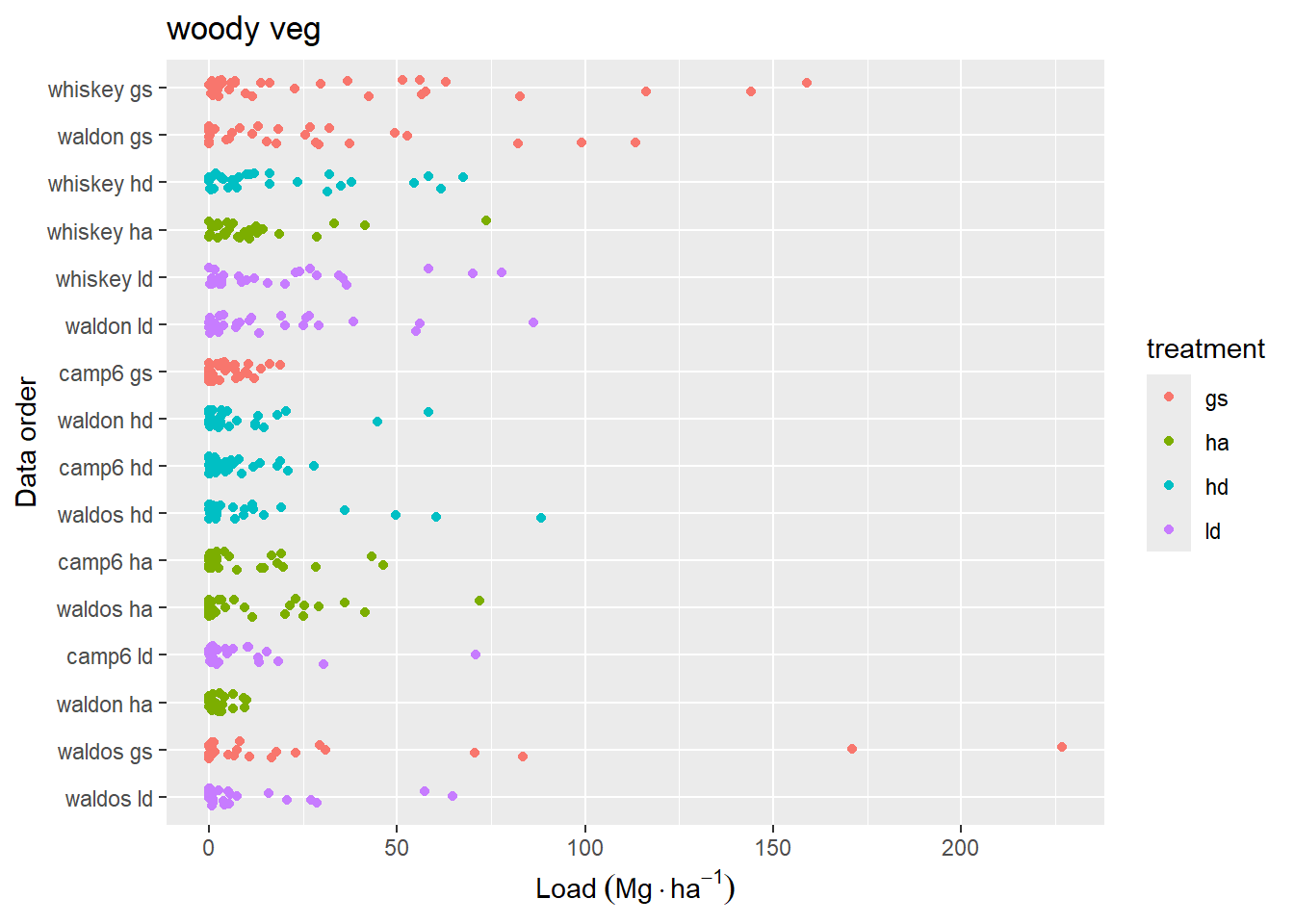
(a) Woody vegetation
(b) herbaceous vegetation
Figure 4.6: Vegetation fuel loading for each station along transects, including live and dead fuels attached to live vegetation. Y-axis is sorted as in Figure 4.4.
4.3 Normality
For further testing, I will summarize the data somewhat, by combining vegetation loading (woody and herb), and coarse woody loading (sound and rotten) into just two loading metrics. Now we have the following response variables:
dufflitter
onehr
tenhr
hundhr
thoushr
veg
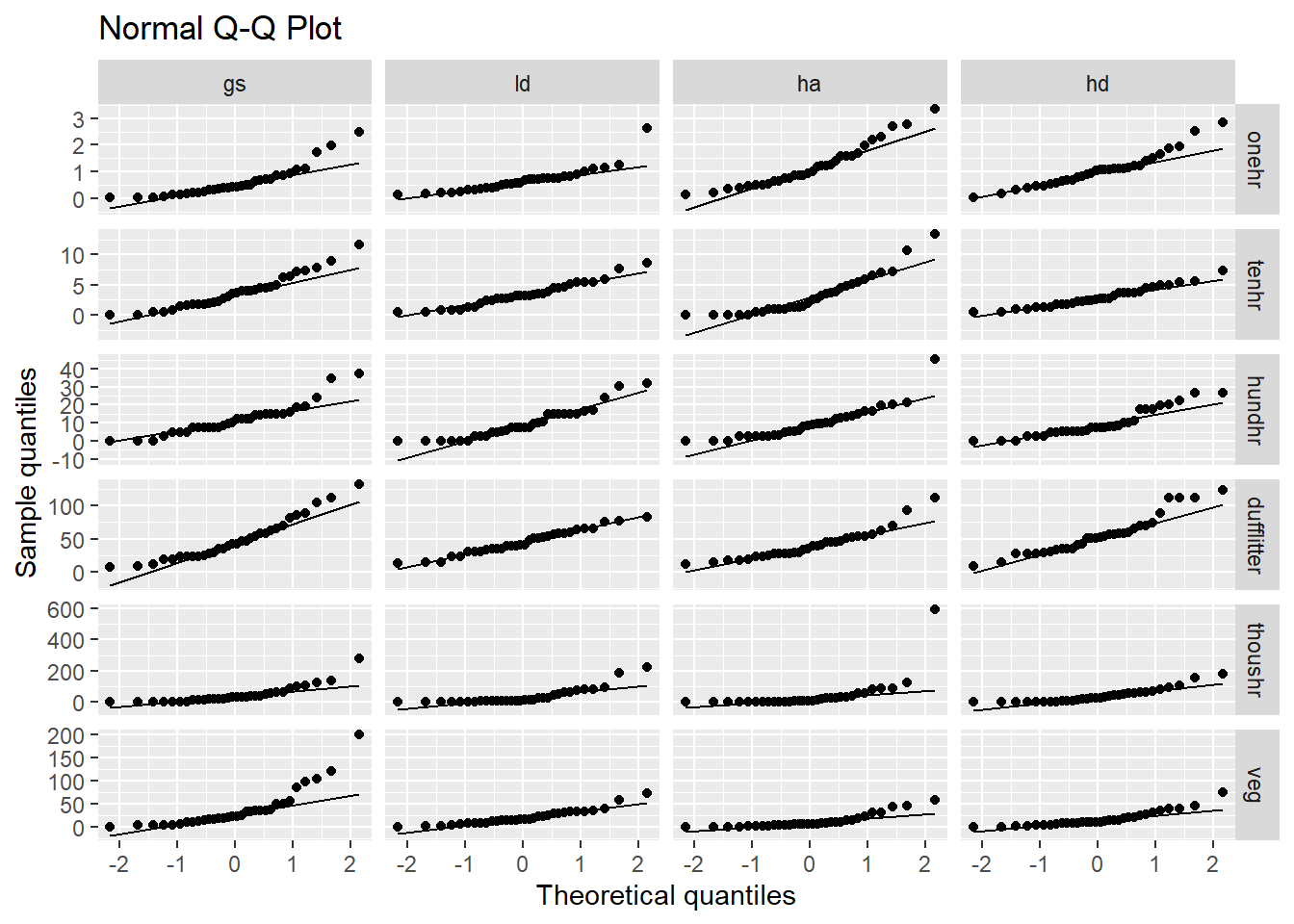
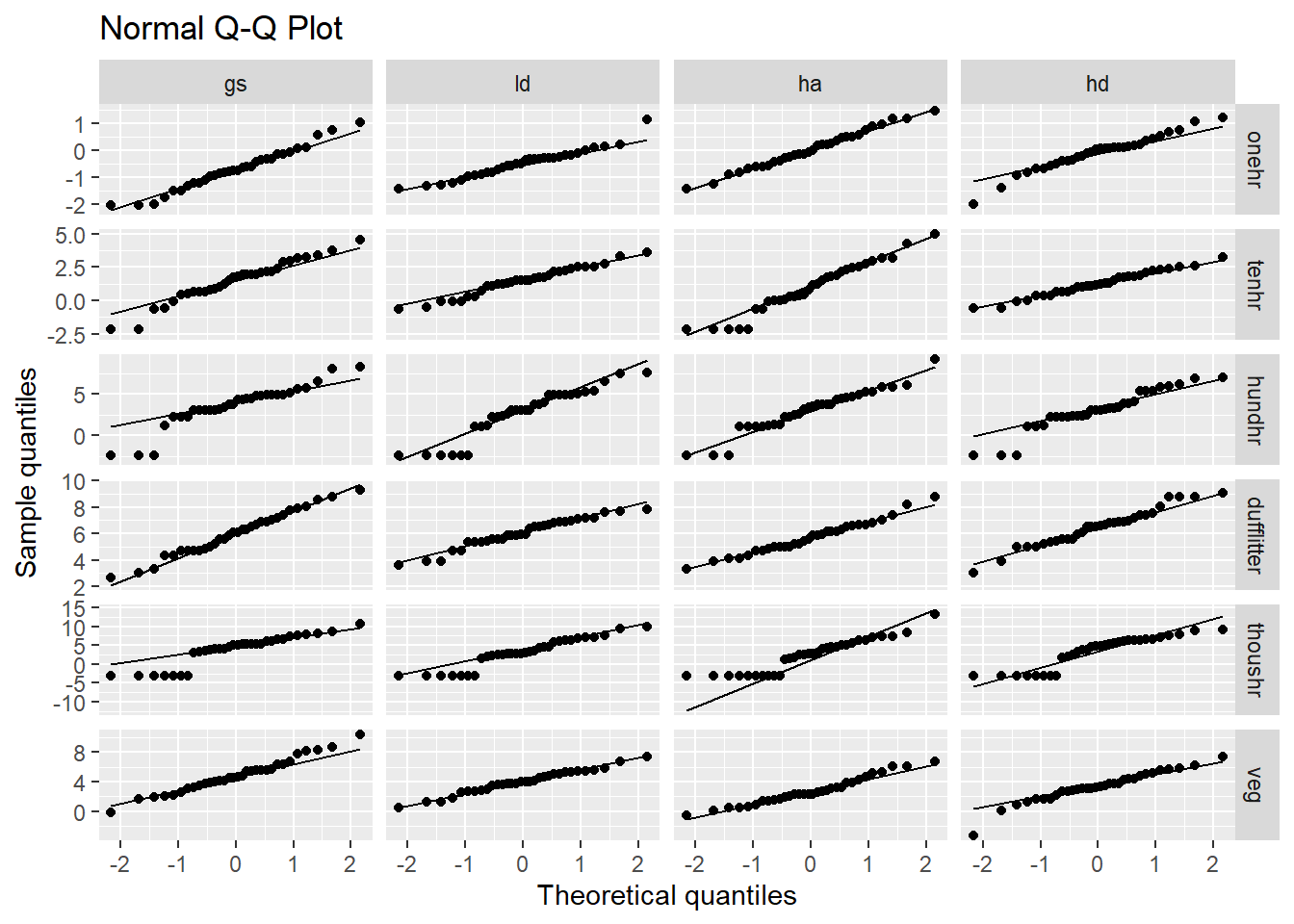
When using manova to test for difference between groups with multiple response variables, it is important that the response variables are multivariate normally distributed. Unfortunately, it would appear that we have a probelem with normality. The raw data for each loading variable is clearly not normally distributed Figure 4.7.
Figure 4.7: Naive qq plot of loading variables. This doesn’t take into the fact that our data is nested. You could say this is based on a simple model where all observations are independent.
Code
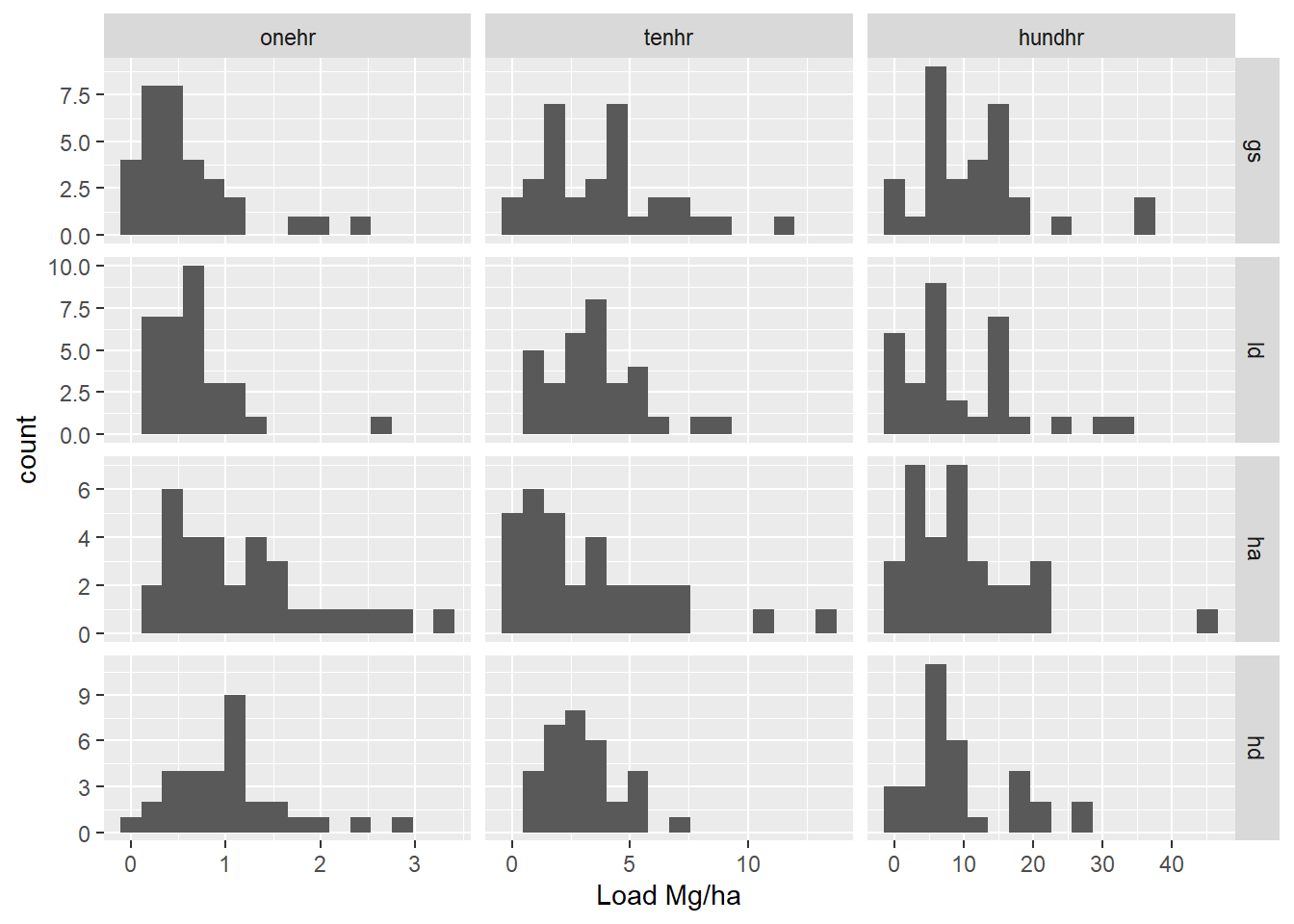
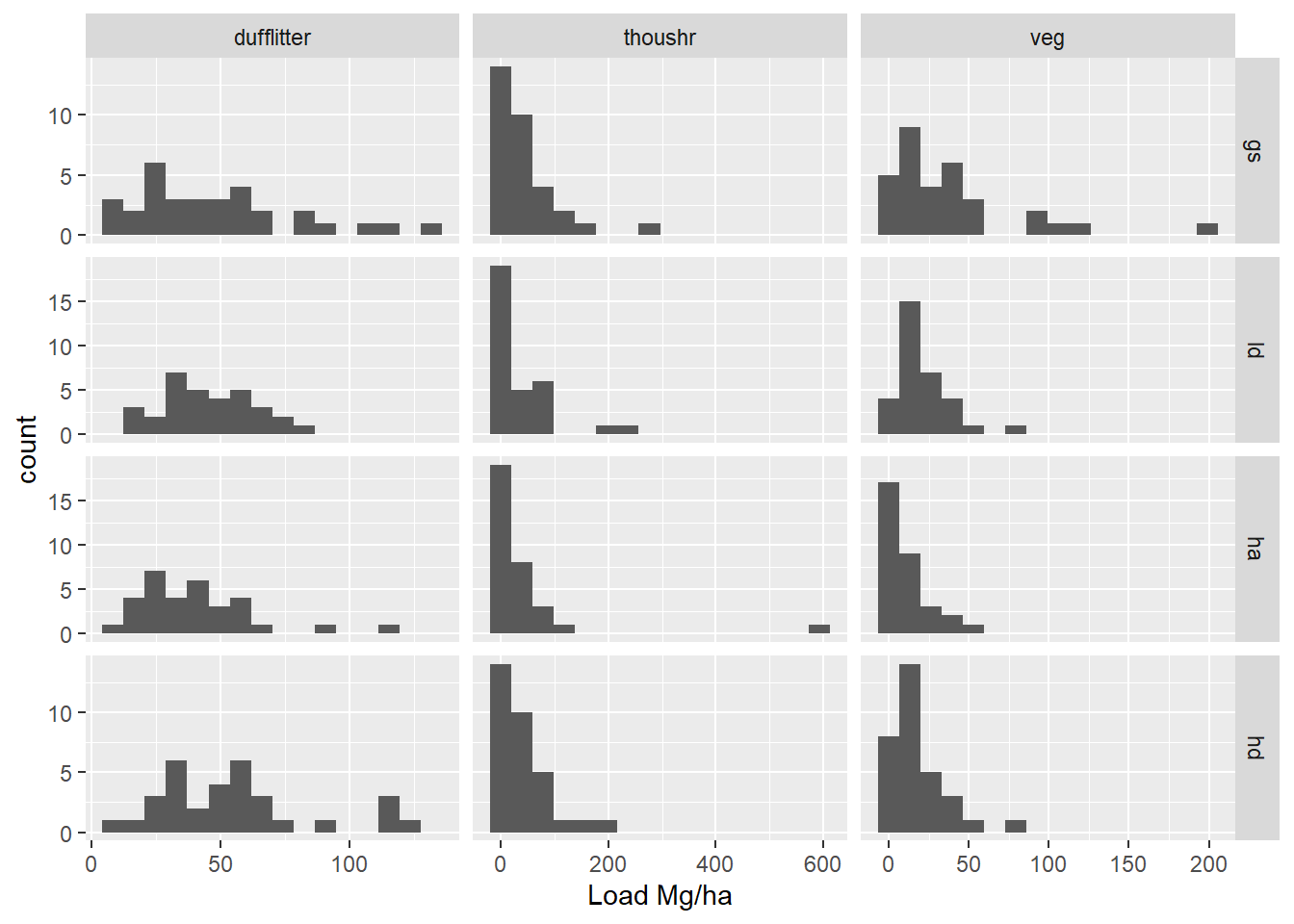
# This code creates a dataframe with nested columns that include the original# data and calculated coordinates of a superimposed normal distribution.# TODO: why does this inlcude site corner azi?bins <-16hist_dat <-load2("long", "pre", all_of(treatment_load_vars)) |>drop_na() |># Facet grid each column (class) has same scale, find limits to calculate bin# width, limits are either implied by the constructed normal curce, or the raw# datagroup_by(class) |>mutate(xmin =min(c(mean(load) -3*sd(load), load)),xmax =max(c(mean(load) +3*sd(load), load)) ) |>group_by(treatment, class) |>nest(data = load) |># generate data for a normal curve with mean and sd from observed data to# cover 3 sd.mutate(norm_x =map(data, function(d) {seq(from =mean(d$load) -3*sd(d$load),to =mean(d$load) +3*sd(d$load),length.out =100 ) }),# scale curve to expected binwidth based on plot layout (same x scale across# all fuel classes) multiplied by the number of observations. The histogram# and normal curve should represent the same total area.norm_y =map(data, function(d) { dens <-dnorm(unlist(norm_x), mean =mean(d$load), sd =sd(d$load)) dens * ((xmax - xmin) / bins) *nrow(d) }) )# here is the code to plot the above data. I decided not to use this after all,# but it was a lot of work, so I'm keeping it for posterity# nolint start# ggplot(filter(hist_dat, class %in% load_vars[1:3] )) +# geom_histogram(data = \(x) unnest(x, data), aes(x = load), bins = bins) +# geom_line(data = \(x) unnest(x, c(norm_x, norm_y)), aes(norm_x, norm_y)) +# facet_grid(treatment ~ class, scales = "free") +# labs(y = "count", x = "Load Mg/ha")## ggplot(filter(hist_dat, class %in% load_vars[4:6] )) +# geom_histogram(data = \(x) unnest(x, data), aes(x = load), bins = bins) +# geom_line(data = \(x) unnest(x, c(norm_x, norm_y)), aes(norm_x, norm_y)) +# facet_grid(treatment ~ class, scales = "free") +# labs(y = "count", x = "Load Mg/ha")# nolint end
While, this looks somewhat more normal, the zeros end up being a little strange. I applied a separate transformation for each fuel class, but all treatments within a fuel class have the same transformation.
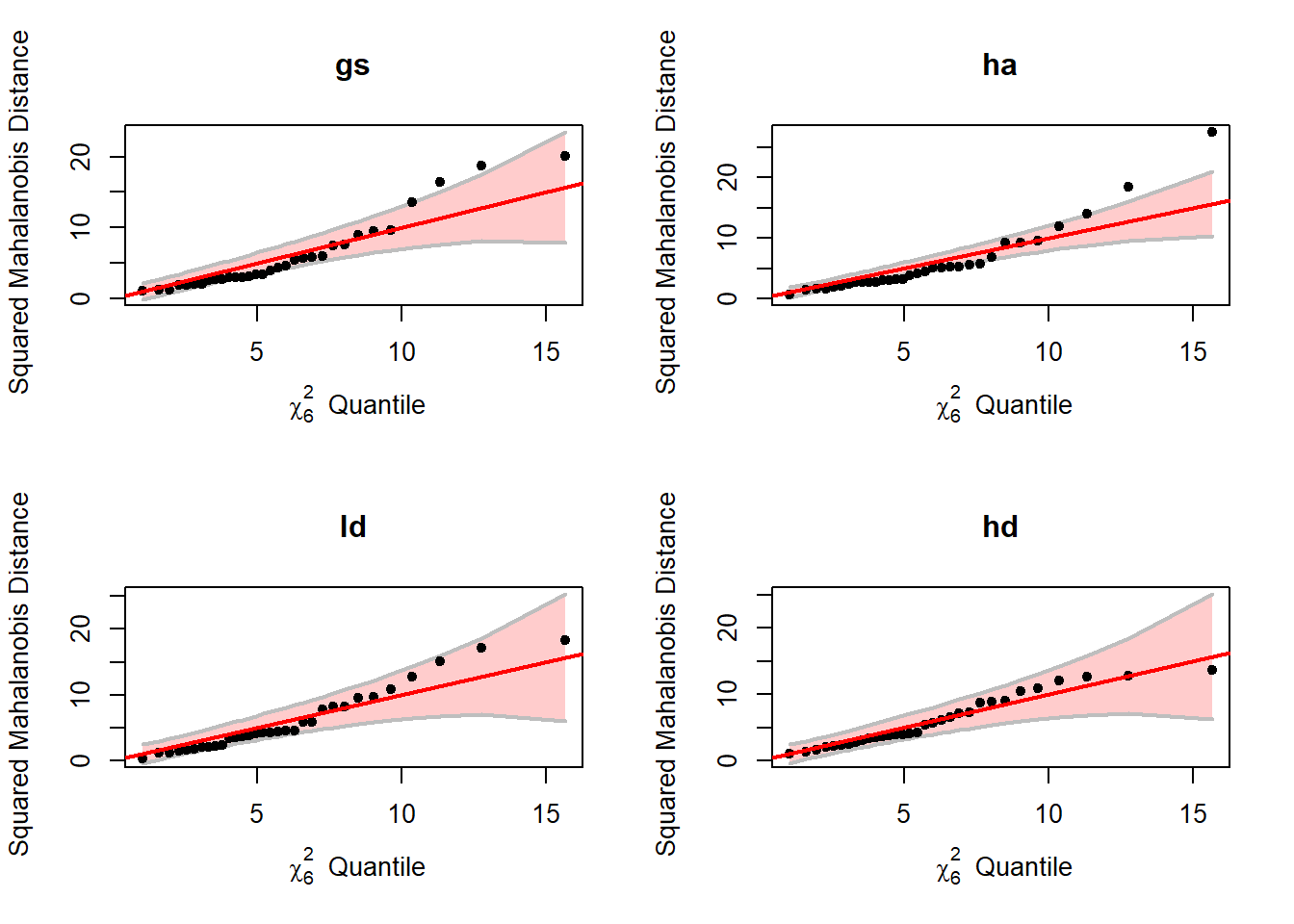
For MANOVA we are concerned with the within group multivariate normality, the assumption does not appear to be met here either (Figure 4.9). The code output below indicates the rows with the greatest deviation from normal.
Table 4.2: Several different tests of multivariate normality indicate a lack of evidence to support this assumption.
treatment
Test
statistic
p value
Result
gs
Mardia Skewness
156.2386
0.0000
NO
gs
Mardia Kurtosis
4.1306
0.0000
NO
ld
Mardia Skewness
122.0012
0.0000
NO
ld
Mardia Kurtosis
3.2534
0.0011
NO
ha
Mardia Skewness
198.9055
0.0000
NO
ha
Mardia Kurtosis
5.8903
0.0000
NO
hd
Mardia Skewness
85.1671
0.0072
NO
hd
Mardia Kurtosis
0.7268
0.4673
YES
gs
Henze-Zirkler
1.1979
0.0000
NO
ld
Henze-Zirkler
1.1036
0.0001
NO
ha
Henze-Zirkler
1.2792
0.0000
NO
hd
Henze-Zirkler
1.0978
0.0001
NO
gs
Royston
79.7755
0.0000
NO
ld
Royston
65.9480
0.0000
NO
ha
Royston
105.5921
0.0000
NO
hd
Royston
51.6106
0.0000
NO
gs
Doornik-Hansen
45.8165
0.0000
NO
ld
Doornik-Hansen
38.4513
0.0001
NO
ha
Doornik-Hansen
57.3566
0.0000
NO
hd
Doornik-Hansen
67.3211
0.0000
NO
gs
E-statistic
1.9038
0.0000
NO
ld
E-statistic
1.7881
0.0000
NO
ha
E-statistic
2.1409
0.0000
NO
hd
E-statistic
1.6312
0.0000
NO
4.3.2 Other distributions
If our data is not normally distributed, then what distribution is it? I’m going to assume what we are interested in the distribution of data within groups (treatments).
I attemped to model the distribution of our conditional response data (fuel size class by treatment), but it mostly didn’t work.
Our data is non-negative (contains zeros) continuous (for the most part) and highly variable in terms of skew and kurtosis. The presence of zeros, makes using the Gamma distribution more difficult. One possibility is a hurdle gamma, or Zero-adjusted Gamma.
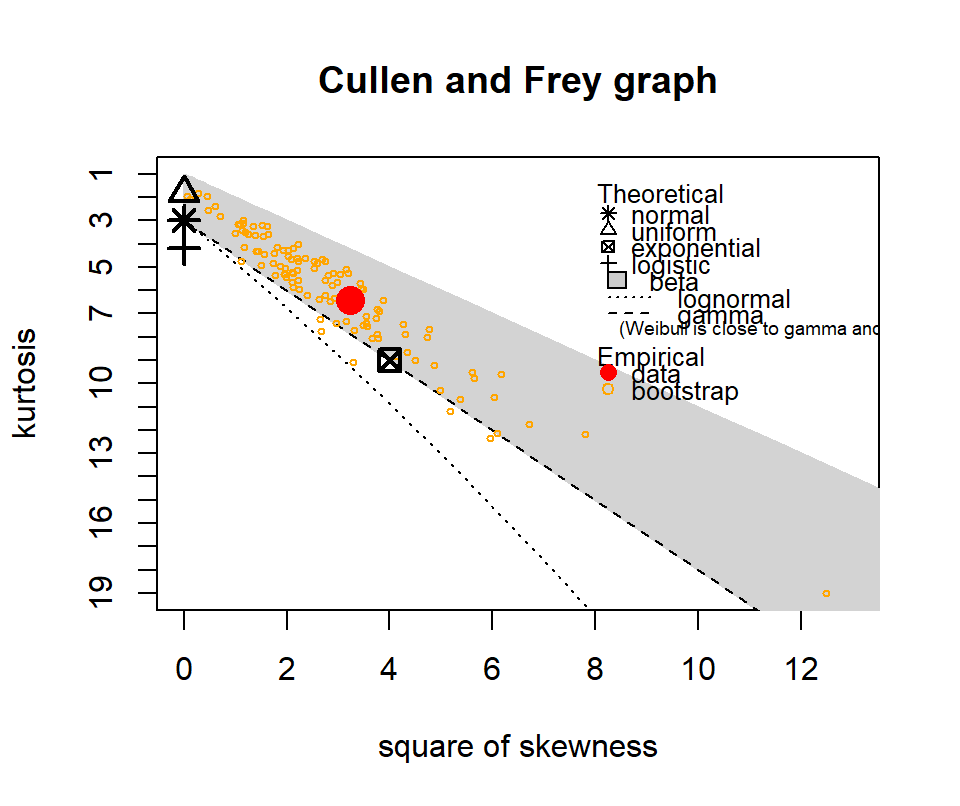
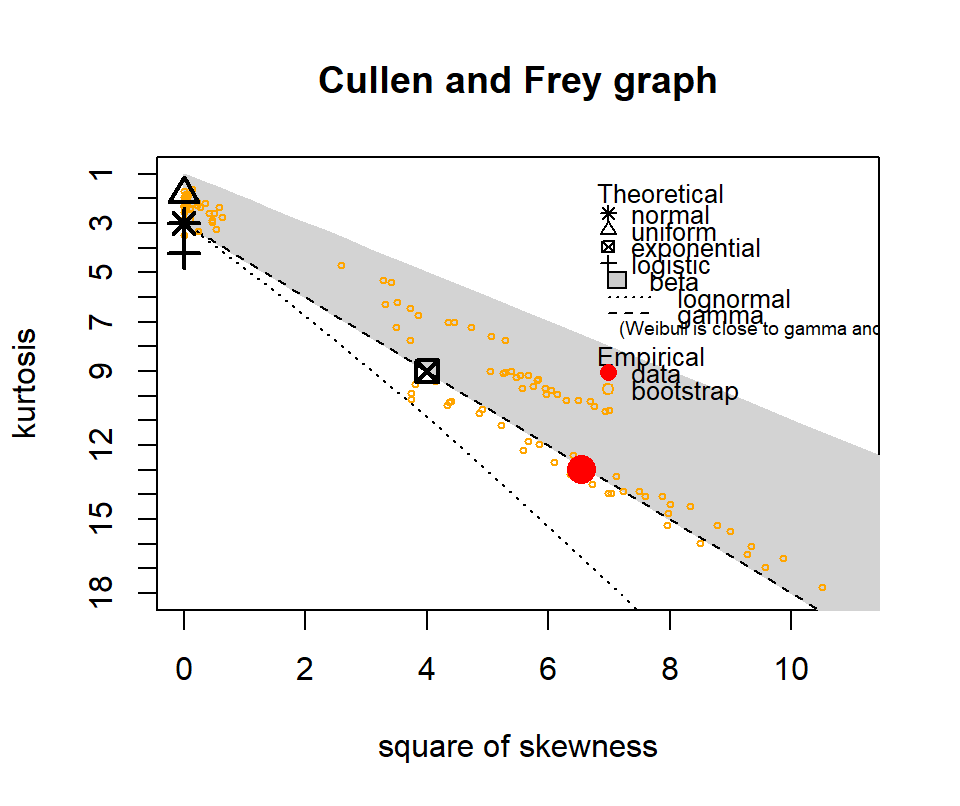
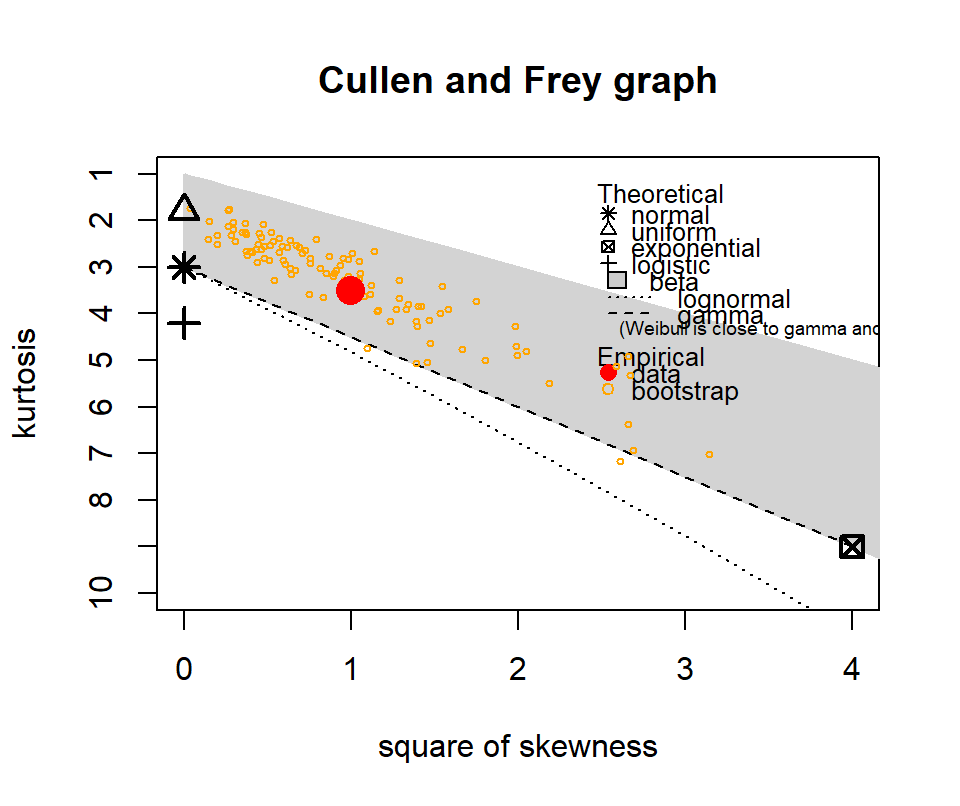
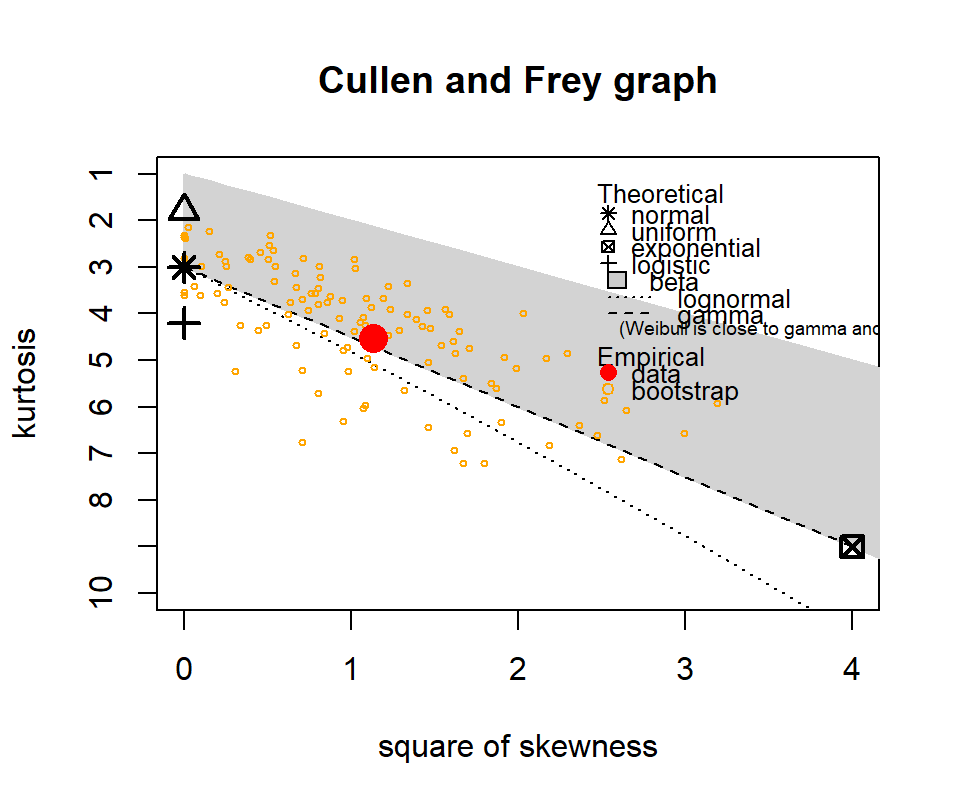
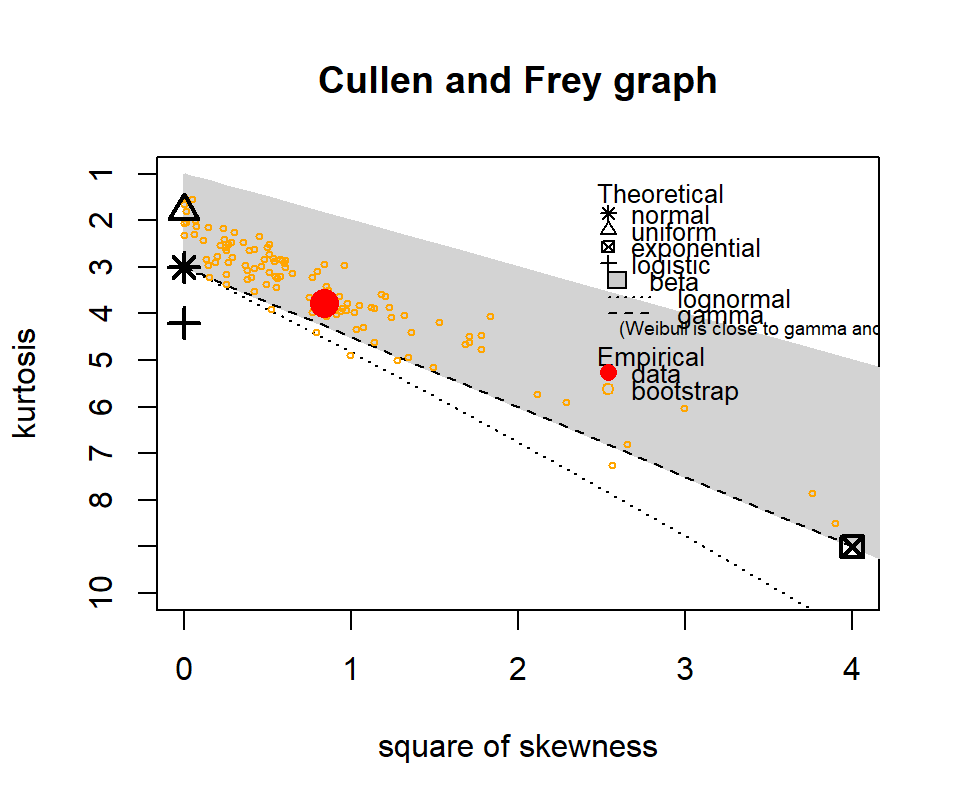
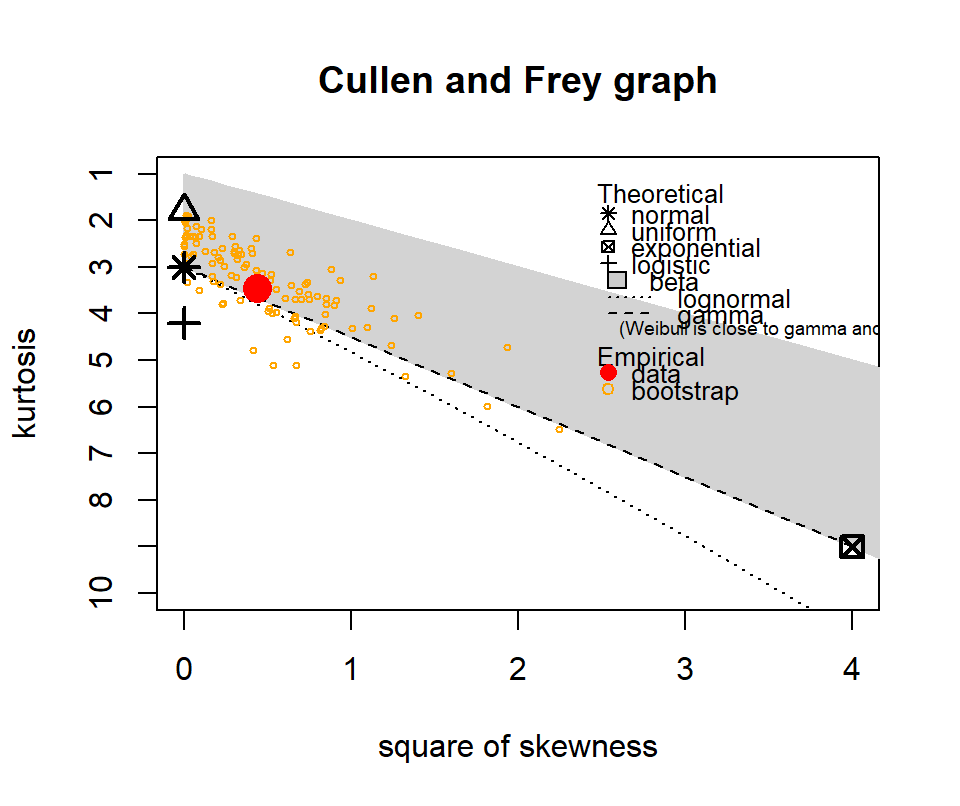
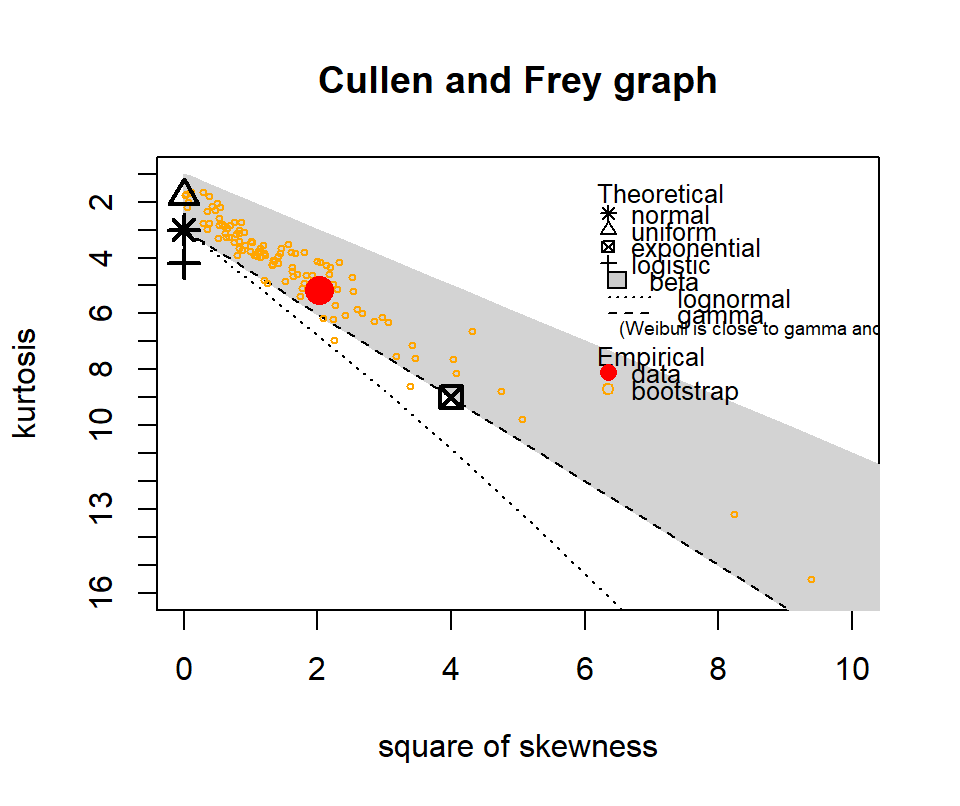
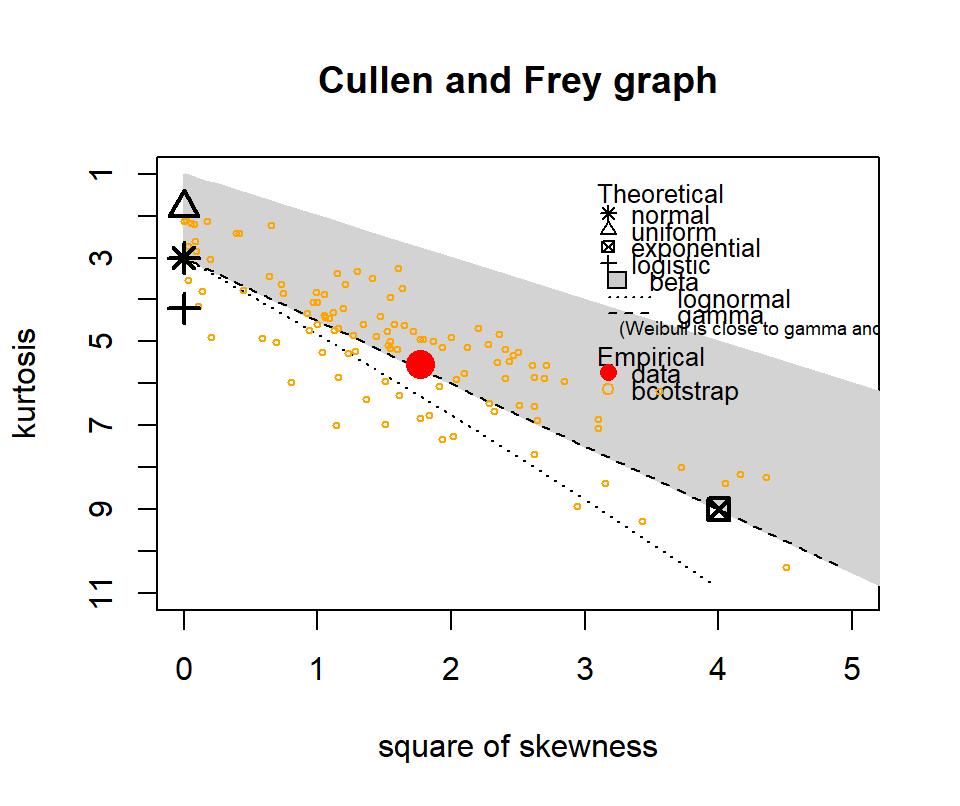
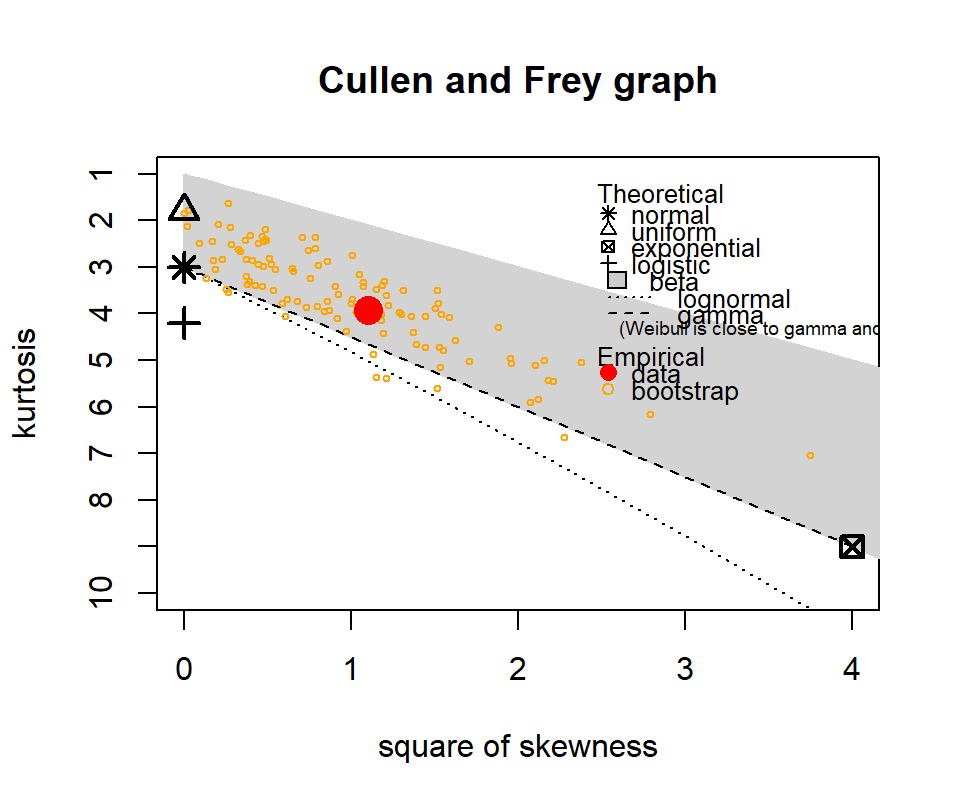
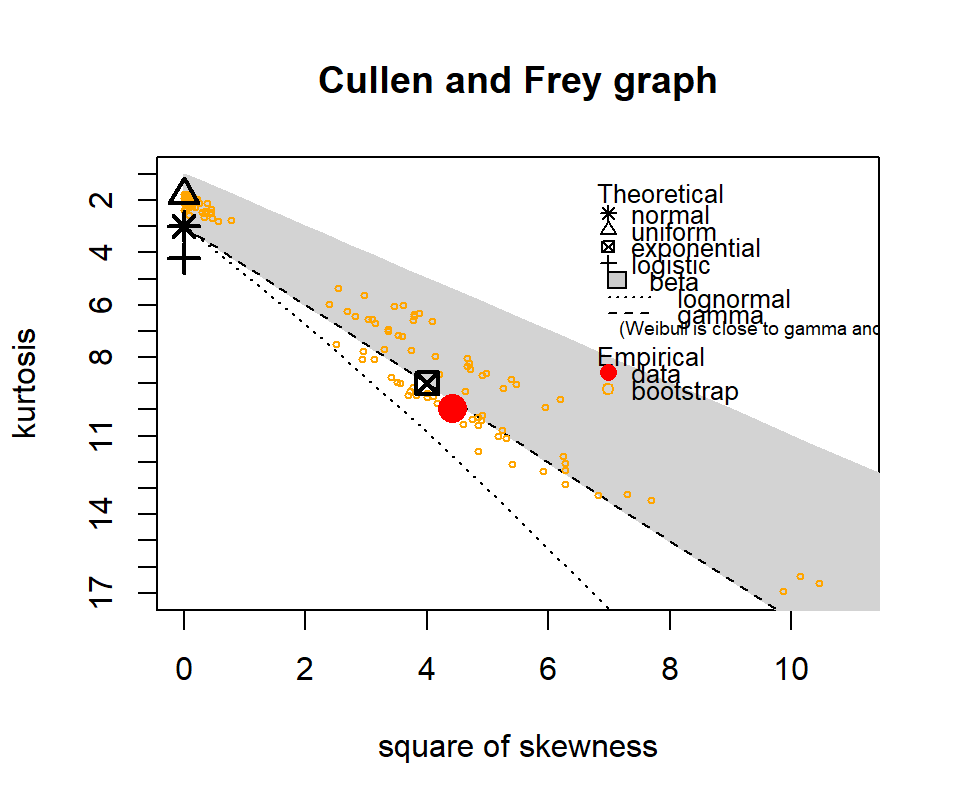
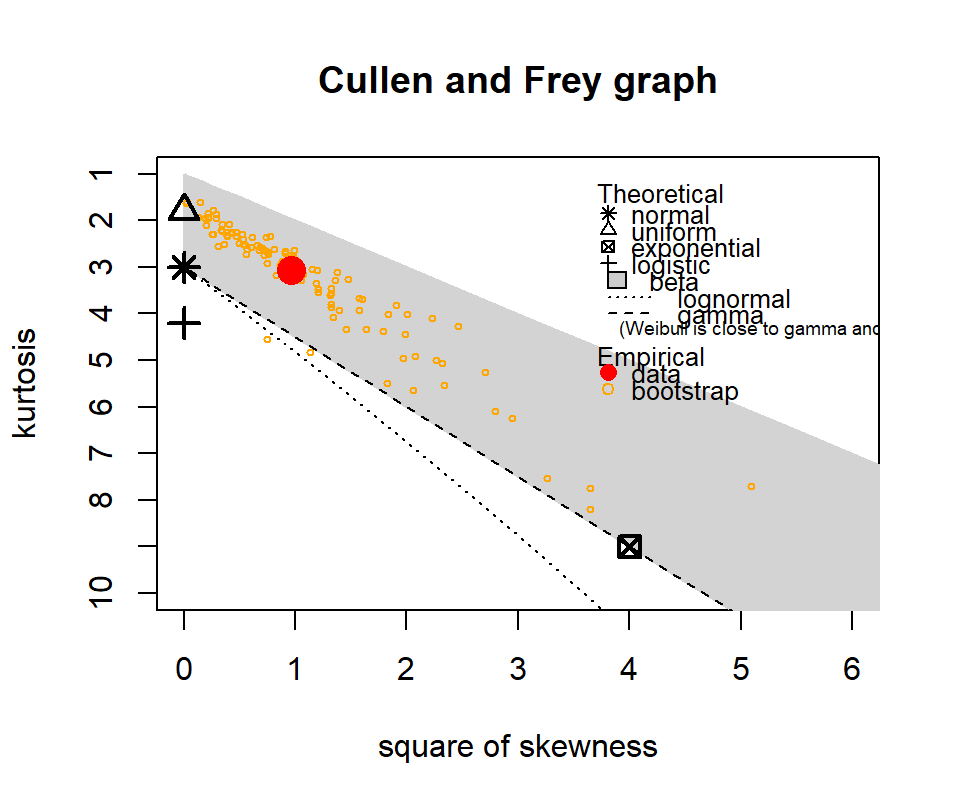
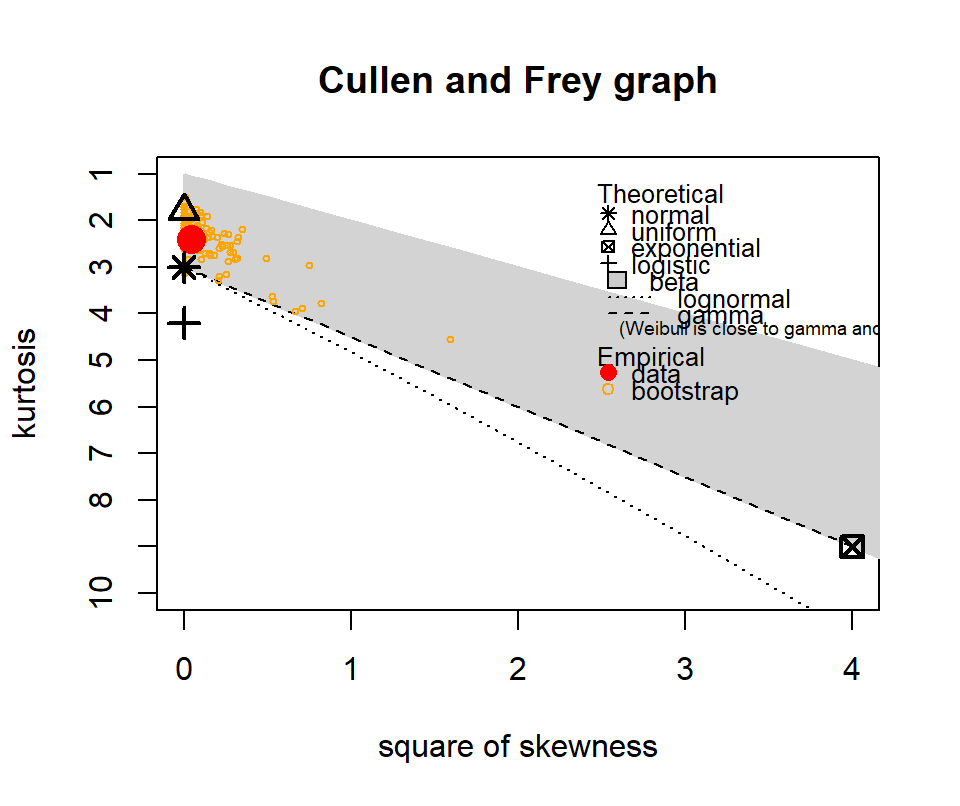
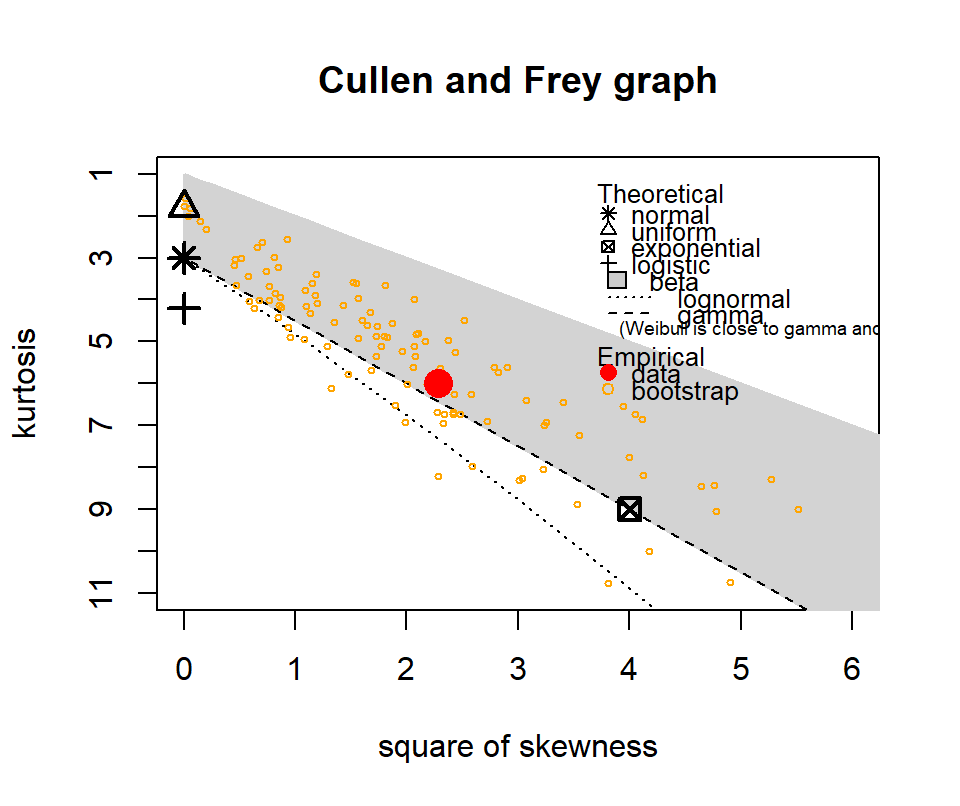
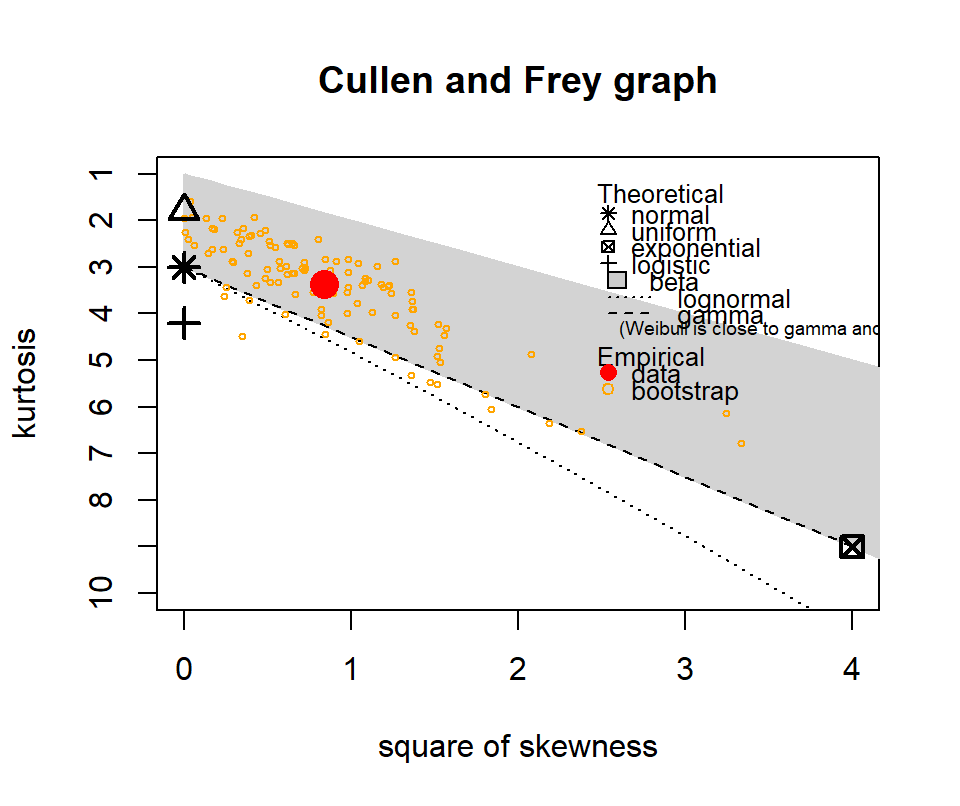
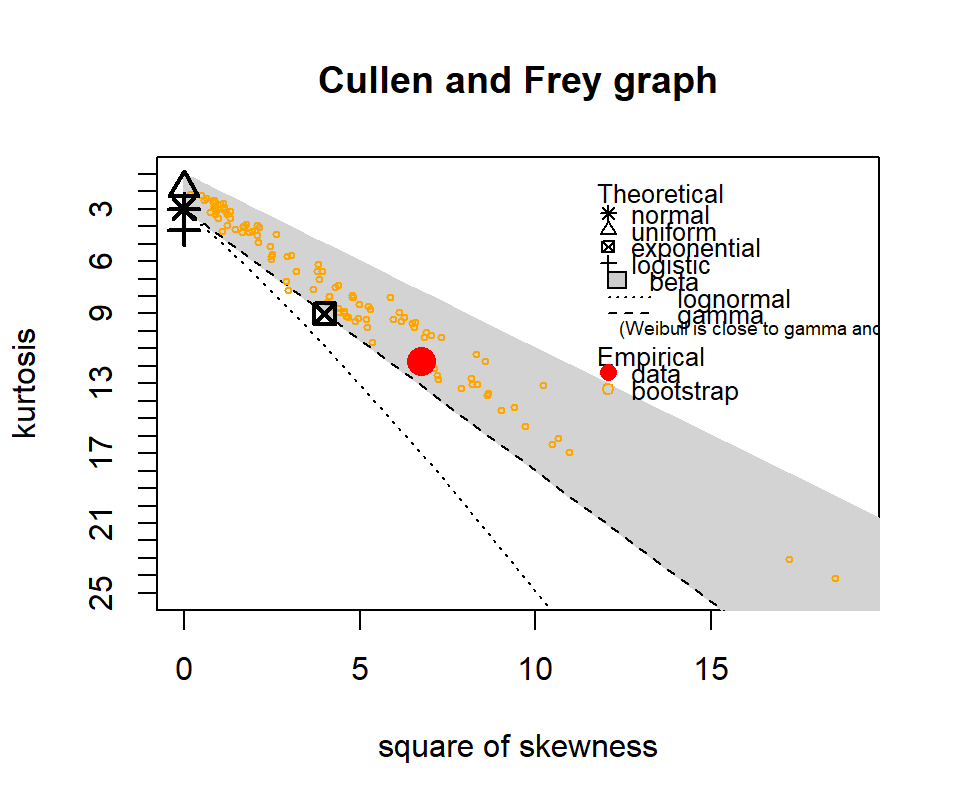
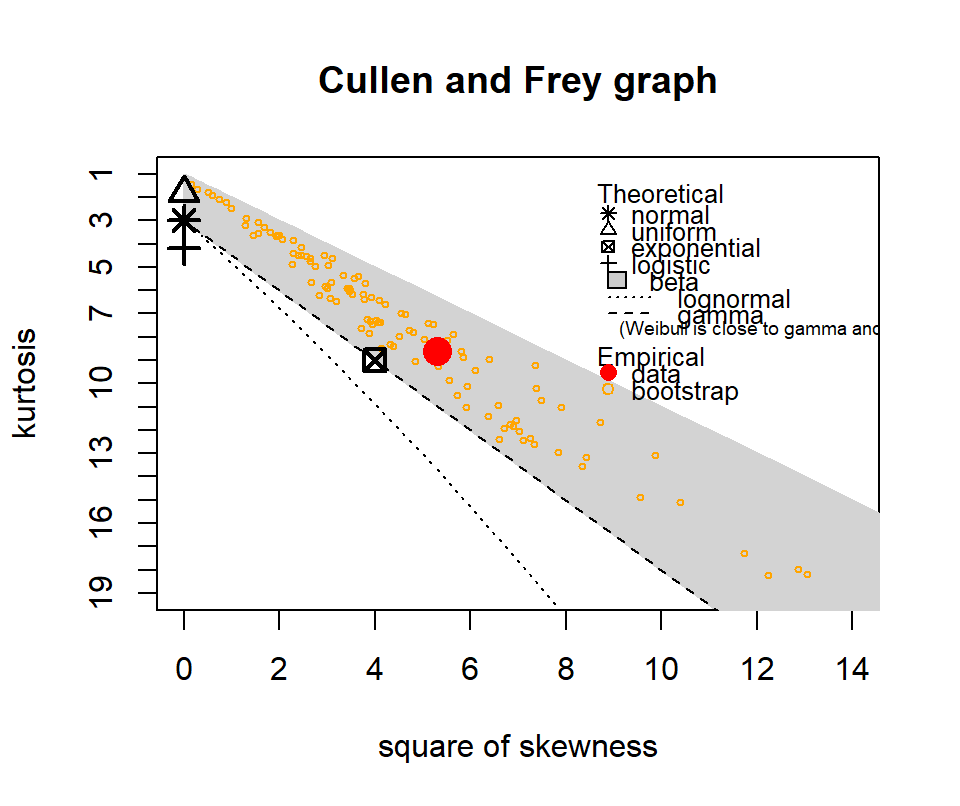
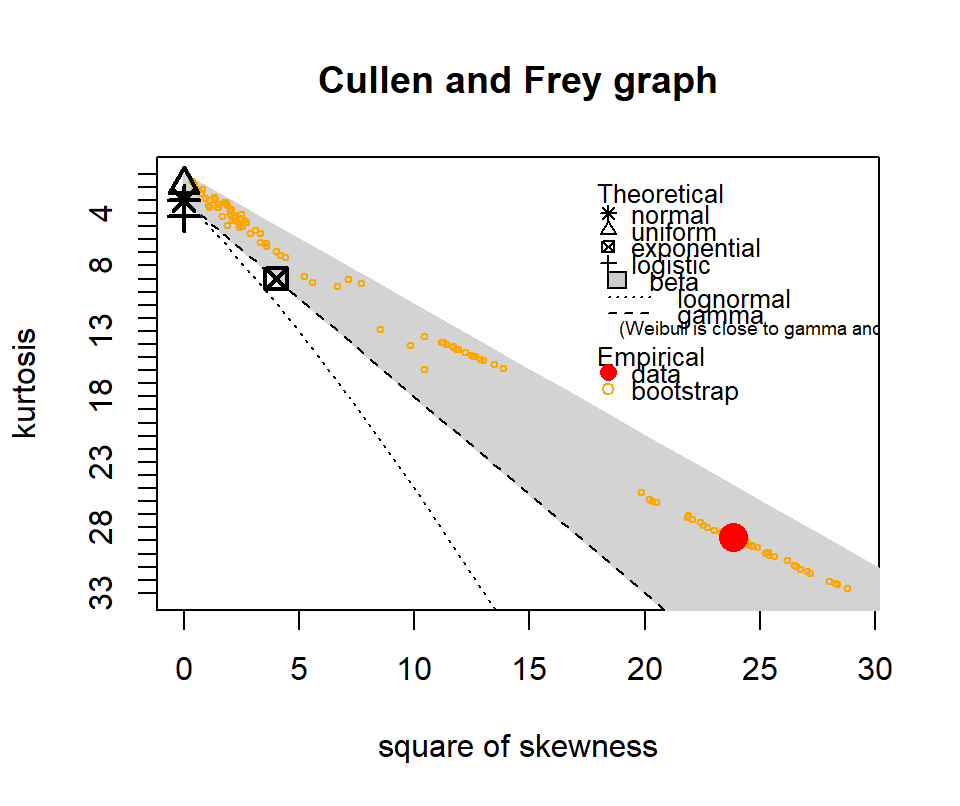
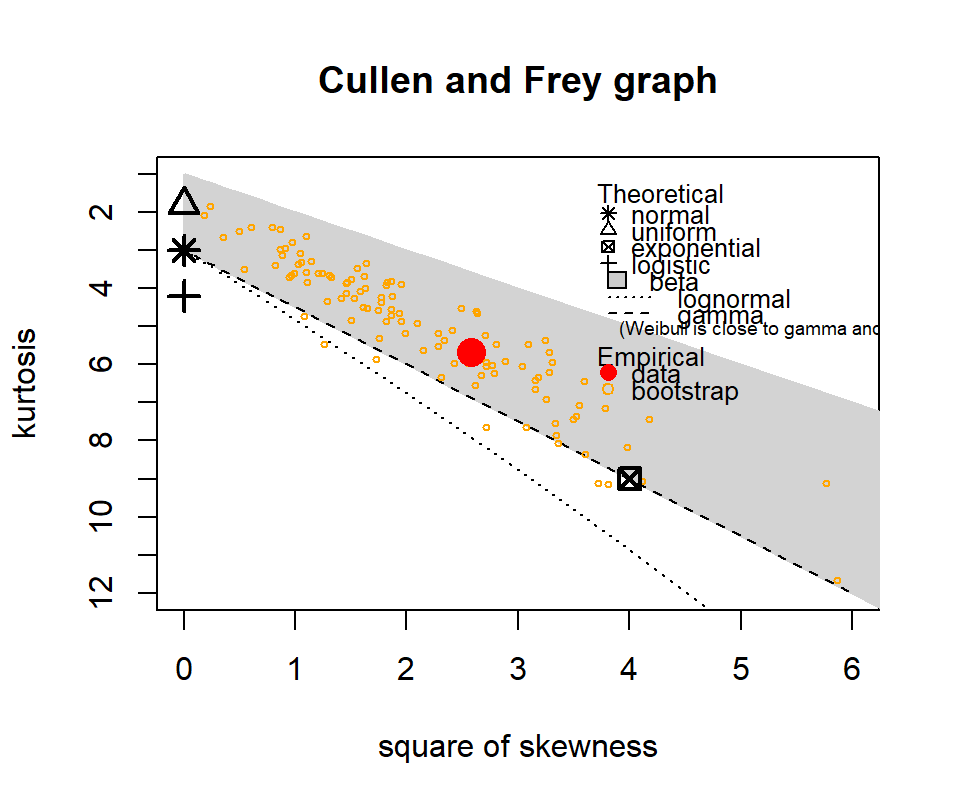
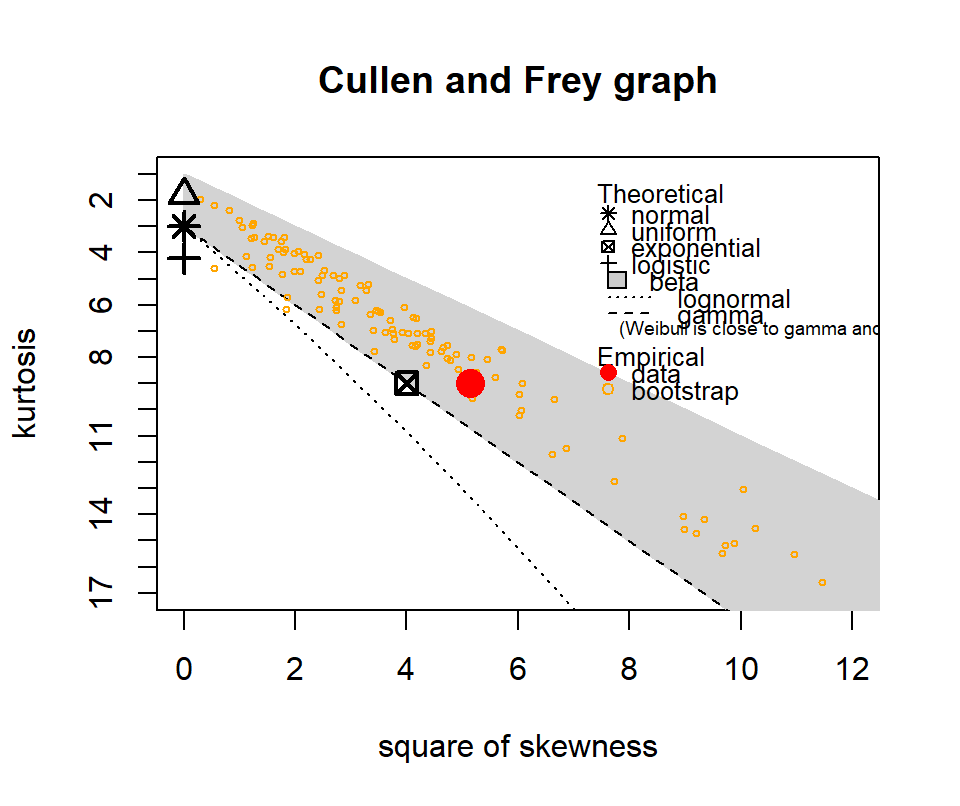
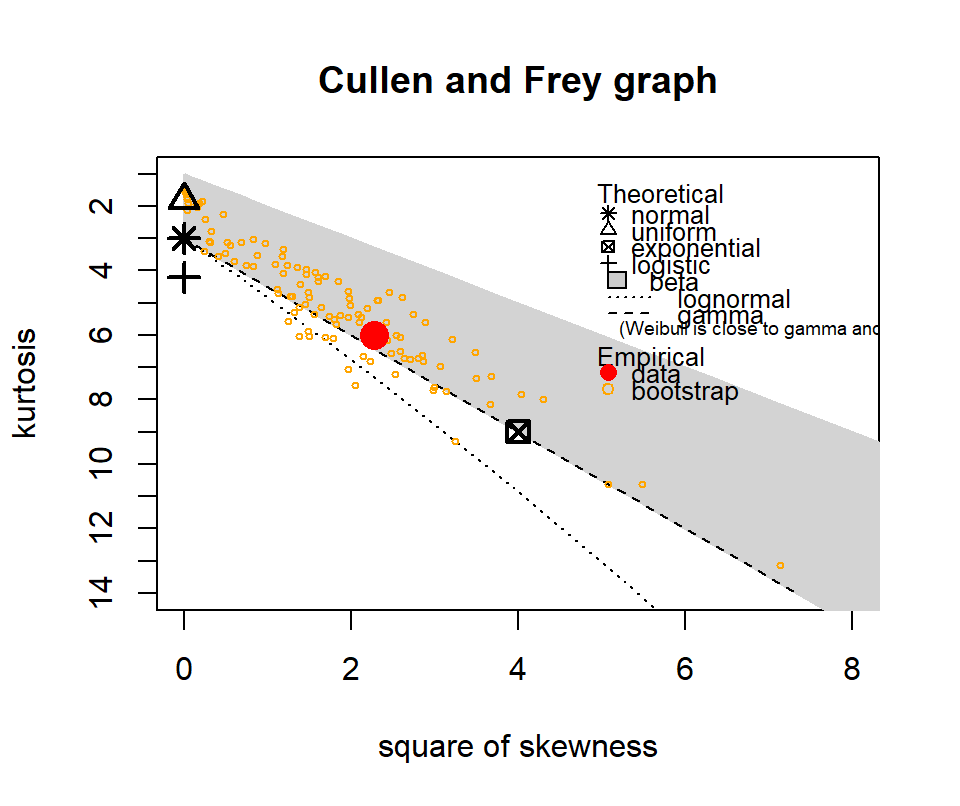
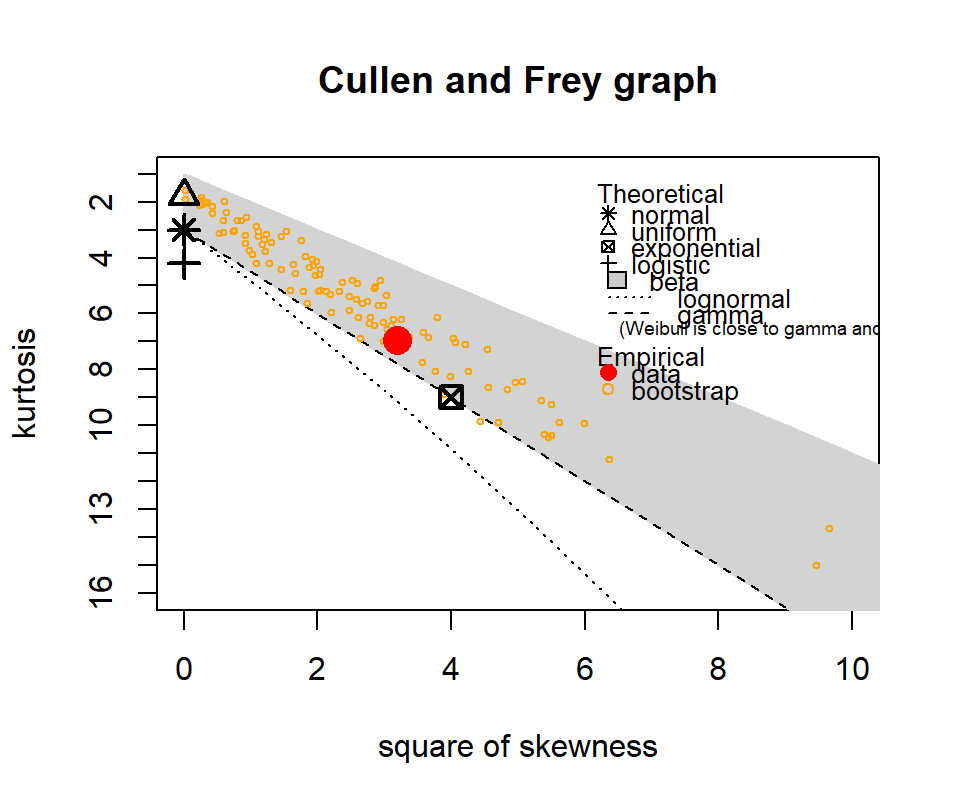
The following show where our data lies in terms of kurtosis and skewness compared to other common distributions. It looks somewhat Gamma-ish?
Figure 4.10: Skewness and kurtosis for fuel classes within treatments.
4.3.3 Zero-adjusted Gamma
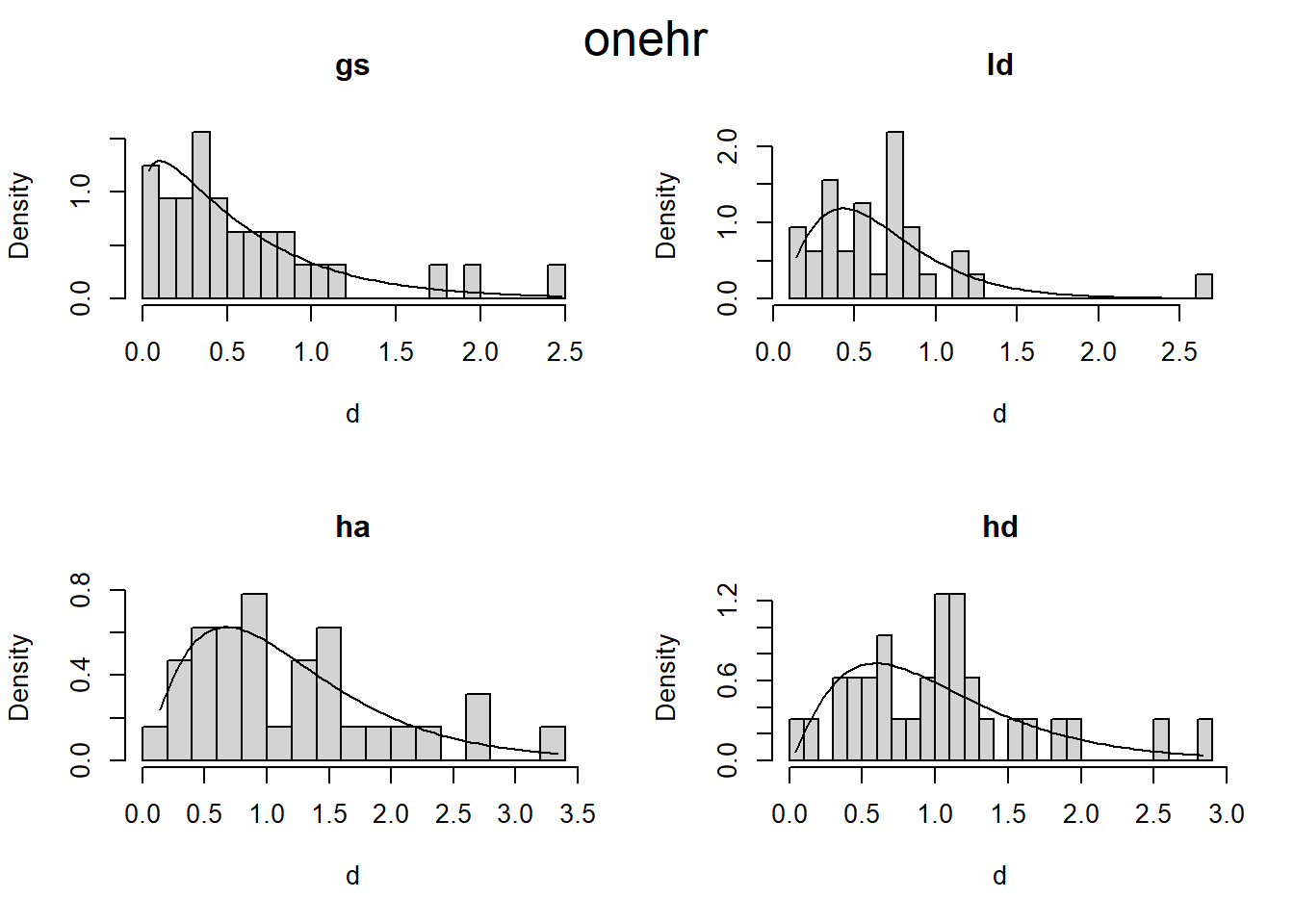
I’ll try using the gamlss package, which fits models “where all the parameters of the assumed distribution for the response can be modelled as additive functions of the explanatory variables.”
I’m not really sure how it works, but I know if will allow me to fit a model assuming a gamma distribution, while modeling the zeros separately. First I fit a model, then I get the estimated distribution parameters, then I plot the density curve over a histrogram (scaled to density). This looks promising to me.
Code
# Zero adjusted Gamma distribution fit to histogramsplot_zaga <-function(i, d) { m1 <- gamlss::gamlssML(d, family = gamlss.dist::ZAGA())hist(d, prob =TRUE, main = i, breaks =20)curve( gamlss.dist::dZAGA(x, mu = m1$mu, sigma = m1$sigma, nu = m1$nu), # nolintfrom =min(d),to =max(d),add =TRUE )}plot_zaga_class <-function(data, class_name) {if (missing(class_name)) { class_name <-as.character(substitute(data)) class_name <- class_name[length(class_name)] }par(mfrow =c(2, 2))iwalk(data, ~plot_zaga(.y, .x))mtext(class_name, cex =1.6, side =3, line =-2, outer =TRUE)}d2 <- d |>map(~map(.x, "load"))iwalk(d2, ~plot_zaga_class(.x, .y))
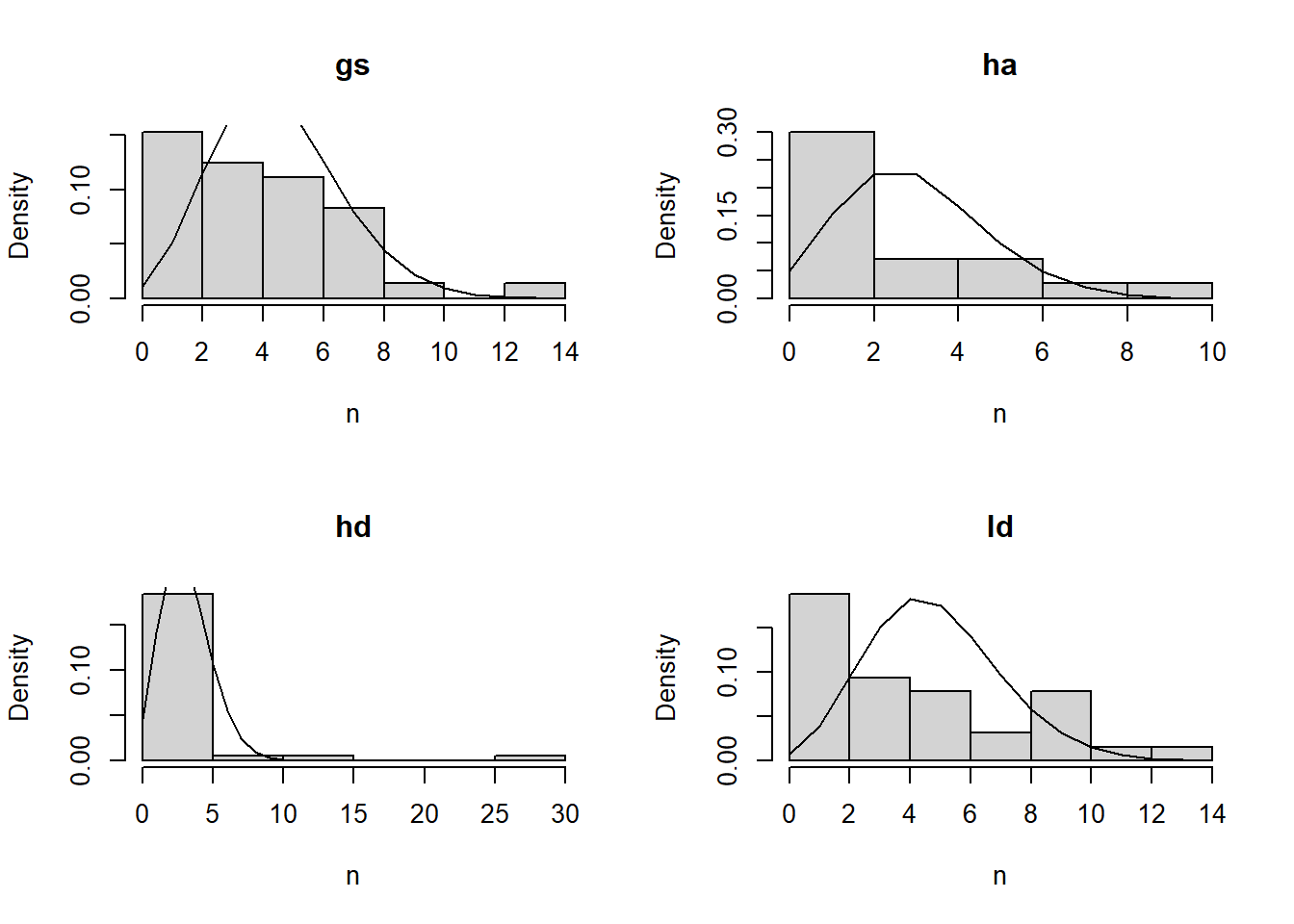
4.3.4 Poisson fit of count data
All of the woody debris can be viewed as count data, and mean diameter. The mean diameter implies a distribution, which we actually have for coarse woody, but not for FWD.
I wonder If I can model these counts as a Poisson process.
That didn’t look so great, so I also tried using a Zero-inflated Poisson distribution, but the model fit an extremely small value for the parameter that controls the probability of zero (referred to here as sigma) and so was effectively the same as the Poisson fit.
# A tibble: 4 × 2
# Groups: treatment [4]
treatment sigma
<chr> <dbl>
1 gs 0.134
2 ha 0.0775
3 hd 0.267
4 ld 0.0568
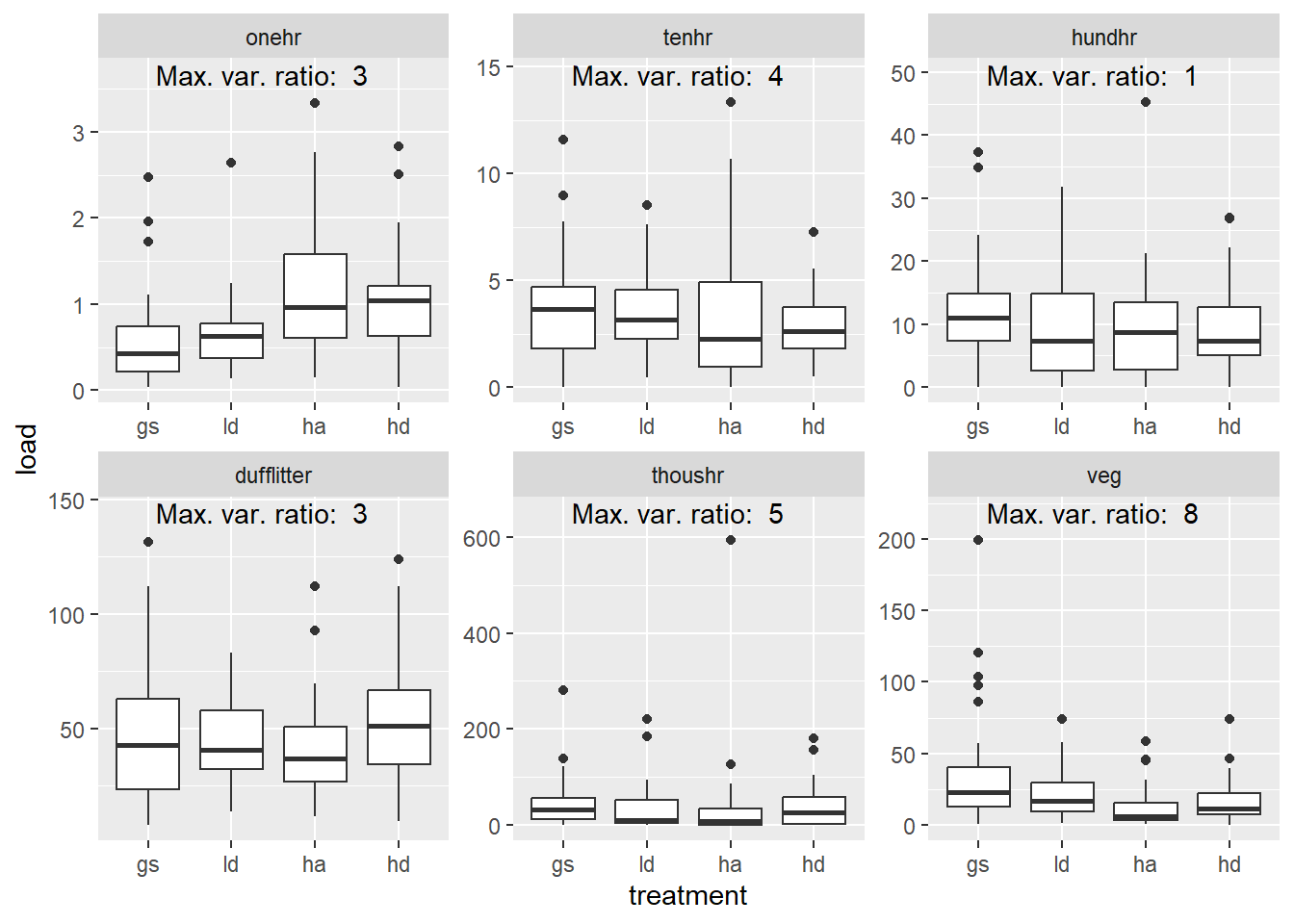
4.4 Homogeneity of variance
There seem to be some pretty big differences in the variance between treatments. This is likely to do with outliers. For linear regression, it is recommended that maximum variance ration should be below 4.
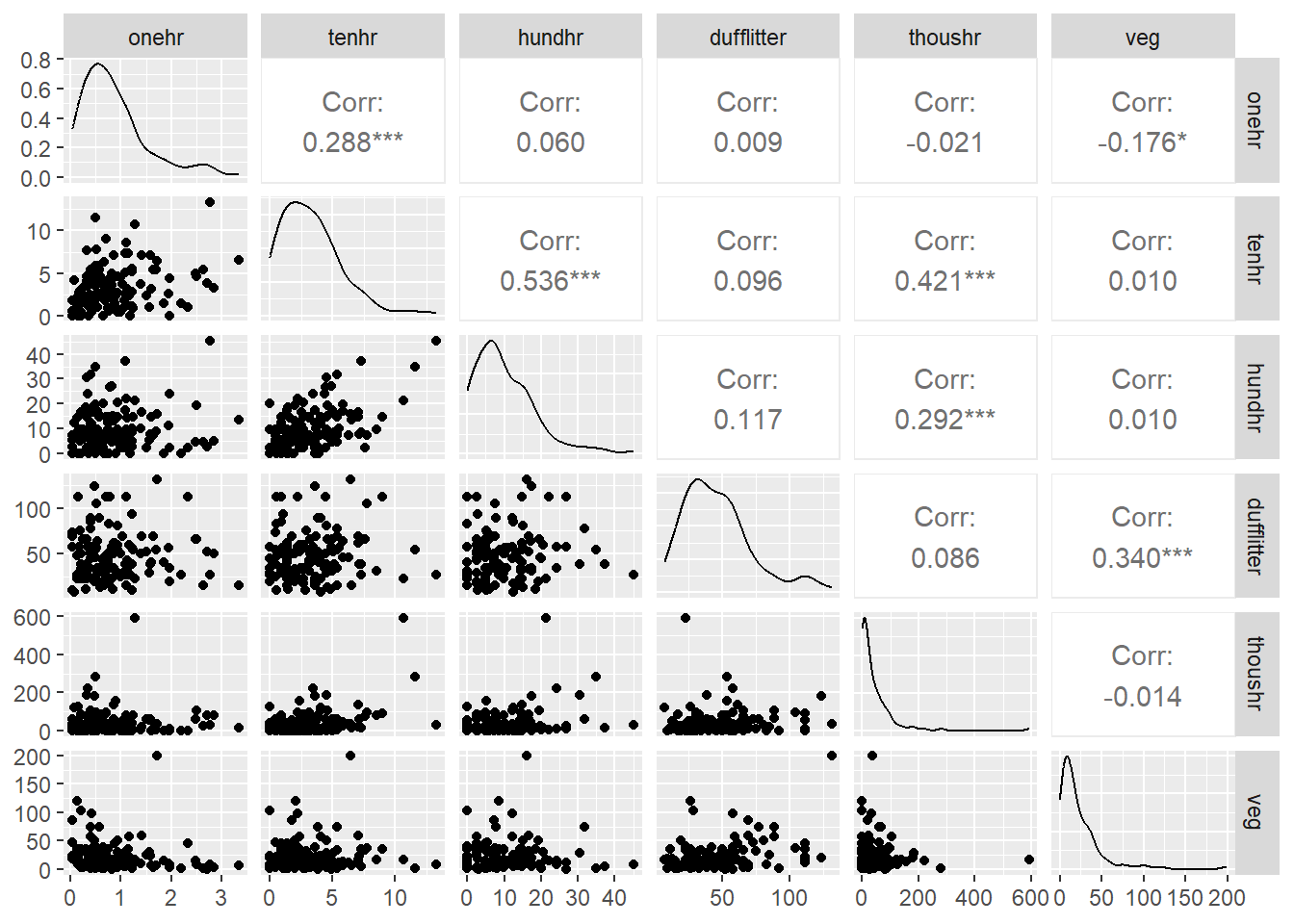
I’m not sure if it’s important, but I was curious if the various fuel loading classes were correlated with each other. Either across the board, or within a given treatment.
Figure 4.11: Correlation among the response variables (fuel classes).
4.7 Independence
Because of how are data were collected they are not independent. The current data is summarized at the transect level. At that level. We have two transects at each corner. Because of spatial autocorrelation, these may be correlated with each other. Corners (and thus transects) are nested within plots, and plots are within treatments. Each plot received a different treatment. What I’m not clear about is: should I include a random variable for plots, if I’m including a fixed effect for treatment?
There are also question about at what level to summarize/model the data. I’ve already averaged stations within transects for several variable that were collected at the station level (two within each transect). What are the trade-offs for either averaging at the corner level, or alternatively, analyzing our raw station data instead of averaging.
Zuur, A. F., Ieno, E. N., & Elphick, C. S. (2010). A protocol for data exploration to avoid common statistical problems. Methods in Ecology and Evolution, 1(1), 3–14. https://doi.org/10.1111/j.2041-210X.2009.00001.x